
Picovoice Leopard and Cheetah offline, on-device speech-to-text engines are said to achieve cloud-level accuracy, rely on tiny Speech-to-Text models, and slash the cost of automatic transcription by up to 10 times.
Leopard is an on-device speech-to-text engine, while Cheetah is an on-device streaming speech-to-text engine, and both are cross-platform with support for Linux x86_64, macOS (x86_64, arm64), Windows x86_64, Android, iOS, Raspberry Pi 3/4, and NVIDIA Jetson Nano.
 Looking at the cost is always tricky since companies have different pricing structures, and the table above basically shows the best scenario, where Picovoice is 6 to 20 times more cost-effective than solutions from Microsoft Azure or Google STT. Picovoice Leopard/Cheetah is free for the first 100 hours, and customers can pay a monthly $999 fee for up to 10,000 hours hence the $0.1 per hour cost with PicoVoice. If you were to use only 1000 hours out of your plan that would be $1 per hour, still not too bad. Check out the pricing page for details.
Looking at the cost is always tricky since companies have different pricing structures, and the table above basically shows the best scenario, where Picovoice is 6 to 20 times more cost-effective than solutions from Microsoft Azure or Google STT. Picovoice Leopard/Cheetah is free for the first 100 hours, and customers can pay a monthly $999 fee for up to 10,000 hours hence the $0.1 per hour cost with PicoVoice. If you were to use only 1000 hours out of your plan that would be $1 per hour, still not too bad. Check out the pricing page for details.
But the price is not everything, and a cheap service that does not do the job would be worthless, so the company provided some speech-to-text benchmarks with instructions to reproduce their setup on Github comparing Picovoice Leopard/Cheetah against AWS Transcribe, Google STT/STT-Enhanced, IBM Watson STT, and Microsoft Azure.
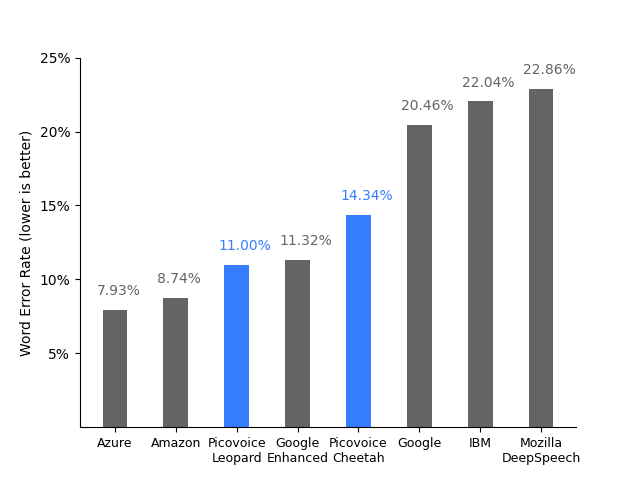
The first metric looked into is the word error rate to estimate the accuracy of the services/solutions. Picovoice Leopard and Cheetah achieve a relatively low word error rate similar to cloud-based services such as Azure, Amazon, and Google Enhanced, and much better than Mozilla DeepSpeech offline, on-device speech-to-text engine.
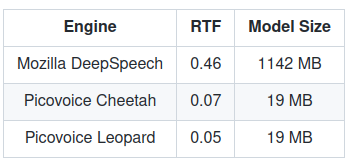
Mozilla DeepSpeech would still be the most cost-effective solution (since it’s free) provided your application can do with the lower accuracy, but another aspect is that Picovoice speech-to-text engines make use of much fewer resources than the Mozilla STT solution with a lower Real-Time Factor (RTF), the ratio of CPU processing time to the length of the input speech file, and acoustic and language models that are 60 times smaller.
The closed-source libraries for all supported platforms, as well as documentation, can be found on Github in the respective Cheetah and Leopard repositories.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress



Interesting but does it manage many languages ? Like French for example 😅
It only works in English now, but support for German, French and Spanish languages is expected later in 2022, and other languages should/may be supported in 2023 depending on market demand.
Funny how far the benchmark numbers diverge depending on the dataset. The numbers shown on the diagram picture, being an average between the 5 speech datasets Picovoice chose for their benchmark, seem to be very highly driven by how badly each speech-to-text model/service f*cks up on the CommonVoice dataset. Ironically, that’s the dataset collected by mozilla themselves and where Mozilla DeepSpeech has the worst hangups.
The sad thing with Mozilla DeepSpeech is that in 2020, Mozilla CEO Mitchell Baker fired first 70 then 250 more Mozilla employees (out of a staff ca. 1000), among which, iirc, the Rust team and… the DeepSpeech team… due to “shrinking revenues” she said, while she herself has raised her own CEO salary to over 3M$ by 2020 (from 2 458 350$ in 2018 which was already a 400% raise since 2008). The git repo of DeepSpeech seems rather dead since.
Looks like the core figures of Mozilla’s DeepSpeech team around Kelly Davis have started their own startup, coqui, and continue working on an open-source offline STT (which iirc they at first touted as being “compatible” to Mozilla DeepSpeech, but i don’t see any mention of that any more).
Anyways, another interesting option for offline Speech-to-Text would be the Flashlight integrated ASR app (formerly wav2letter++) by Facebook AI Research. It’s in C++, MIT-licensed and has GPU support (alas CUDA only) which accelerates training a lot. I didn’t quickly find benchmarks, but from what a quick search tells me, they apparently achieved best (SOTA) performance on Librispeech in 2019.
Some of the links in the Flashlight section were messed up (The same link was repeated three times), I made some changes, but not sure those are the right links.