
When I wrote about Bangle.js 2 JavaScript smartwatch yesterday, I noticed they used “Heatshrink compression” in ESPruino firmware. I can’t remember ever reading about Heatshrink before, and indeed there are no results while searching on CNX Software.
Heatshrink is an open-source data compression library designed for resources-constrained embedded systems that works with as little as 50 bytes of RAM. That’s impressive, so let’s investigate.
The library is written in C language and was released about 8 years ago on Github with the following key features:
- Low memory usage – As low as 50 bytes with specific parameters, and usually under 300 bytes are needed.
- Incremental, bounded CPU use – Input data is processed in tiny bites
- Static or dynamic memory allocation
- Released under an ISC license which allows you to use the library freely, even in commercial products.
The internal workings of the library are explained as follows:
Heatshrink is based on LZSS, since it’s particularly suitable for compression in small amounts of memory. It can use an optional, small index to make compression significantly faster, but otherwise can run in under 100 bytes of memory. The index currently adds 2^(window size+1) bytes to memory usage for compression, and temporarily allocates 512 bytes on the stack during index construction (if the index is enabled).
So let’s give it a try on my laptop, which I reckon is not exactly a resources-constrained embedded system.
|
1 2 3 |
git clone https://github.com/atomicobject/heatshrink cd heatshrink/ make |
After the build is complete we’ll get the libraries (libheatshrink_dynamic.a
and libheatshrink_static.a) which you could use with the header files to integrate into your own project, as well as one 109KB binary (27KB after being stripped) called heatshrink used to encode and decode files. Note that when compiled for an Arduino microcontroller with avr-gcc, the decoder only takes about 1 KB of storage space.
But before using the utilities, we must understand the three options:
- window_sz2, -w – Sets the window size to 2^W bytes. The window size determines how far back in the input can be searched for repeated patterns. A window_sz2 of 8 will only use 256 bytes (2^8), while a window_sz2 of 10 will use 1024 bytes (2^10) with tradeoffs in terms of memory usage and compression ratio. It can be set between 4 and 15.
- lookahead_sz2, -l – Sets the lookahead size to 2^L bytes. The lookahead size determines the max length for repeated patterns that are found. For instance, if the lookahead_sz2 is 4, a 50-byte run of ‘a’ characters will be represented as several repeated 16-byte patterns (2^4 is 16). It’s usually set to around half the size of windows_sz2
Let compress/encode the latest Linux 5.14 changelog with heatshrink using 8/4 and 13/4 parameters:
|
1 2 3 4 5 6 7 8 9 10 11 |
time ./heatshrink -e -w 8 -l 4 Linux-5.14-Changelog.txt Linux-5.14-Changelog.txt.hs real 0m1.346s user 0m1.323s sys 0m0.016s time ./heatshrink -e -w 13 -l 4 Linux-5.14-Changelog.txt Linux-5.14-Changelog.txt.hs2 real 0m4.689s user 0m4.659s sys 0m0.008s |
It will take longer, and consume more memory and CPU cycles with a larger window size, but the compression ratio is also much better.
|
1 2 3 4 |
ls -l Linux-5.14-Changelog* -rw-rw-r-- 1 jaufranc jaufranc 16282443 Sep 28 20:20 Linux-5.14-Changelog.txt -rw-r--r-- 1 jaufranc jaufranc 10854495 Sep 28 20:22 Linux-5.14-Changelog.txt.hs -rw-r--r-- 1 jaufranc jaufranc 6203196 Sep 28 20:27 Linux-5.14-Changelog.txt.hs2 |
So you’d have to adjust this to optimize the values considering the resources available on your target. To decompress we just need to replace the first argument:
|
1 2 3 4 5 |
time ./heatshrink -d Linux-5.14-Changelog.txt.hs2 Linux-5.14-Changelog-decompressed.txt real 0m0.486s user 0m0.458s sys 0m0.024s |
Decompression is quite faster. A quick check with diff shows the files are identical.
The Makefile also comes with a benchmark option (but I had to download the cantrbry.tar.gz file manually first) that will test various files and settings:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 |
make bench mkdir -p benchmark_out cd benchmark_out && tar vzxf ../cantrbry.tar.gz alice29.txt asyoulik.txt cp.html fields.c grammar.lsp kennedy.xls lcet10.txt plrabn12.txt ptt5 sum xargs.1 time ./benchmark pass: -w 6 -l 5 alice29.txt pass: -w 6 -l 5 asyoulik.txt pass: -w 6 -l 5 cp.html pass: -w 6 -l 5 fields.c pass: -w 6 -l 5 grammar.lsp pass: -w 6 -l 5 kennedy.xls pass: -w 6 -l 5 lcet10.txt pass: -w 6 -l 5 plrabn12.txt pass: -w 6 -l 5 ptt5 pass: -w 6 -l 5 sum pass: -w 6 -l 5 xargs.1 pass: -w 7 -l 5 alice29.txt pass: -w 7 -l 5 asyoulik.txt pass: -w 7 -l 5 cp.html pass: -w 7 -l 5 fields.c pass: -w 7 -l 5 grammar.lsp pass: -w 7 -l 5 kennedy.xls pass: -w 7 -l 5 lcet10.txt pass: -w 7 -l 5 plrabn12.txt pass: -w 7 -l 5 ptt5 pass: -w 7 -l 5 sum pass: -w 7 -l 5 xargs.1 pass: -w 7 -l 6 alice29.txt pass: -w 7 -l 6 asyoulik.txt pass: -w 7 -l 6 cp.html pass: -w 7 -l 6 fields.c pass: -w 7 -l 6 grammar.lsp pass: -w 7 -l 6 kennedy.xls pass: -w 7 -l 6 lcet10.txt pass: -w 7 -l 6 plrabn12.txt pass: -w 7 -l 6 ptt5 pass: -w 7 -l 6 sum pass: -w 7 -l 6 xargs.1 pass: -w 8 -l 5 alice29.txt pass: -w 8 -l 5 asyoulik.txt pass: -w 8 -l 5 cp.html pass: -w 8 -l 5 fields.c pass: -w 8 -l 5 grammar.lsp pass: -w 8 -l 5 kennedy.xls pass: -w 8 -l 5 lcet10.txt pass: -w 8 -l 5 plrabn12.txt pass: -w 8 -l 5 ptt5 pass: -w 8 -l 5 sum pass: -w 8 -l 5 xargs.1 pass: -w 8 -l 6 alice29.txt pass: -w 8 -l 6 asyoulik.txt pass: -w 8 -l 6 cp.html pass: -w 8 -l 6 fields.c pass: -w 8 -l 6 grammar.lsp pass: -w 8 -l 6 kennedy.xls pass: -w 8 -l 6 lcet10.txt pass: -w 8 -l 6 plrabn12.txt pass: -w 8 -l 6 ptt5 pass: -w 8 -l 6 sum pass: -w 8 -l 6 xargs.1 pass: -w 8 -l 7 alice29.txt pass: -w 8 -l 7 asyoulik.txt pass: -w 8 -l 7 cp.html pass: -w 8 -l 7 fields.c pass: -w 8 -l 7 grammar.lsp pass: -w 8 -l 7 kennedy.xls pass: -w 8 -l 7 lcet10.txt pass: -w 8 -l 7 plrabn12.txt pass: -w 8 -l 7 ptt5 pass: -w 8 -l 7 sum pass: -w 8 -l 7 xargs.1 pass: -w 9 -l 5 alice29.txt pass: -w 9 -l 5 asyoulik.txt pass: -w 9 -l 5 cp.html pass: -w 9 -l 5 fields.c pass: -w 9 -l 5 grammar.lsp pass: -w 9 -l 5 kennedy.xls pass: -w 9 -l 5 lcet10.txt pass: -w 9 -l 5 plrabn12.txt pass: -w 9 -l 5 ptt5 pass: -w 9 -l 5 sum pass: -w 9 -l 5 xargs.1 pass: -w 9 -l 6 alice29.txt pass: -w 9 -l 6 asyoulik.txt pass: -w 9 -l 6 cp.html pass: -w 9 -l 6 fields.c pass: -w 9 -l 6 grammar.lsp pass: -w 9 -l 6 kennedy.xls pass: -w 9 -l 6 lcet10.txt pass: -w 9 -l 6 plrabn12.txt pass: -w 9 -l 6 ptt5 pass: -w 9 -l 6 sum pass: -w 9 -l 6 xargs.1 pass: -w 9 -l 7 alice29.txt pass: -w 9 -l 7 asyoulik.txt pass: -w 9 -l 7 cp.html pass: -w 9 -l 7 fields.c pass: -w 9 -l 7 grammar.lsp pass: -w 9 -l 7 kennedy.xls pass: -w 9 -l 7 lcet10.txt pass: -w 9 -l 7 plrabn12.txt pass: -w 9 -l 7 ptt5 pass: -w 9 -l 7 sum pass: -w 9 -l 7 xargs.1 pass: -w 9 -l 8 alice29.txt pass: -w 9 -l 8 asyoulik.txt pass: -w 9 -l 8 cp.html pass: -w 9 -l 8 fields.c pass: -w 9 -l 8 grammar.lsp pass: -w 9 -l 8 kennedy.xls pass: -w 9 -l 8 lcet10.txt pass: -w 9 -l 8 plrabn12.txt pass: -w 9 -l 8 ptt5 pass: -w 9 -l 8 sum pass: -w 9 -l 8 xargs.1 pass: -w 10 -l 5 alice29.txt pass: -w 10 -l 5 asyoulik.txt pass: -w 10 -l 5 cp.html pass: -w 10 -l 5 fields.c pass: -w 10 -l 5 grammar.lsp pass: -w 10 -l 5 kennedy.xls pass: -w 10 -l 5 lcet10.txt pass: -w 10 -l 5 plrabn12.txt pass: -w 10 -l 5 ptt5 pass: -w 10 -l 5 sum pass: -w 10 -l 5 xargs.1 pass: -w 10 -l 6 alice29.txt pass: -w 10 -l 6 asyoulik.txt pass: -w 10 -l 6 cp.html pass: -w 10 -l 6 fields.c pass: -w 10 -l 6 grammar.lsp pass: -w 10 -l 6 kennedy.xls pass: -w 10 -l 6 lcet10.txt pass: -w 10 -l 6 plrabn12.txt pass: -w 10 -l 6 ptt5 pass: -w 10 -l 6 sum pass: -w 10 -l 6 xargs.1 pass: -w 10 -l 7 alice29.txt pass: -w 10 -l 7 asyoulik.txt pass: -w 10 -l 7 cp.html pass: -w 10 -l 7 fields.c pass: -w 10 -l 7 grammar.lsp pass: -w 10 -l 7 kennedy.xls pass: -w 10 -l 7 lcet10.txt pass: -w 10 -l 7 plrabn12.txt pass: -w 10 -l 7 ptt5 pass: -w 10 -l 7 sum pass: -w 10 -l 7 xargs.1 pass: -w 10 -l 8 alice29.txt pass: -w 10 -l 8 asyoulik.txt pass: -w 10 -l 8 cp.html pass: -w 10 -l 8 fields.c pass: -w 10 -l 8 grammar.lsp pass: -w 10 -l 8 kennedy.xls pass: -w 10 -l 8 lcet10.txt pass: -w 10 -l 8 plrabn12.txt pass: -w 10 -l 8 ptt5 pass: -w 10 -l 8 sum pass: -w 10 -l 8 xargs.1 pass: -w 11 -l 5 alice29.txt pass: -w 11 -l 5 asyoulik.txt pass: -w 11 -l 5 cp.html pass: -w 11 -l 5 fields.c pass: -w 11 -l 5 grammar.lsp pass: -w 11 -l 5 kennedy.xls pass: -w 11 -l 5 lcet10.txt pass: -w 11 -l 5 plrabn12.txt pass: -w 11 -l 5 ptt5 pass: -w 11 -l 5 sum pass: -w 11 -l 5 xargs.1 pass: -w 11 -l 6 alice29.txt pass: -w 11 -l 6 asyoulik.txt pass: -w 11 -l 6 cp.html pass: -w 11 -l 6 fields.c pass: -w 11 -l 6 grammar.lsp pass: -w 11 -l 6 kennedy.xls pass: -w 11 -l 6 lcet10.txt pass: -w 11 -l 6 plrabn12.txt pass: -w 11 -l 6 ptt5 pass: -w 11 -l 6 sum pass: -w 11 -l 6 xargs.1 pass: -w 11 -l 7 alice29.txt pass: -w 11 -l 7 asyoulik.txt pass: -w 11 -l 7 cp.html pass: -w 11 -l 7 fields.c pass: -w 11 -l 7 grammar.lsp pass: -w 11 -l 7 kennedy.xls pass: -w 11 -l 7 lcet10.txt pass: -w 11 -l 7 plrabn12.txt pass: -w 11 -l 7 ptt5 pass: -w 11 -l 7 sum pass: -w 11 -l 7 xargs.1 pass: -w 11 -l 8 alice29.txt pass: -w 11 -l 8 asyoulik.txt pass: -w 11 -l 8 cp.html pass: -w 11 -l 8 fields.c pass: -w 11 -l 8 grammar.lsp pass: -w 11 -l 8 kennedy.xls pass: -w 11 -l 8 lcet10.txt pass: -w 11 -l 8 plrabn12.txt pass: -w 11 -l 8 ptt5 pass: -w 11 -l 8 sum pass: -w 11 -l 8 xargs.1 pass: -w 12 -l 5 alice29.txt pass: -w 12 -l 5 asyoulik.txt pass: -w 12 -l 5 cp.html pass: -w 12 -l 5 fields.c pass: -w 12 -l 5 grammar.lsp pass: -w 12 -l 5 kennedy.xls pass: -w 12 -l 5 lcet10.txt pass: -w 12 -l 5 plrabn12.txt pass: -w 12 -l 5 ptt5 pass: -w 12 -l 5 sum pass: -w 12 -l 5 xargs.1 pass: -w 12 -l 6 alice29.txt pass: -w 12 -l 6 asyoulik.txt pass: -w 12 -l 6 cp.html pass: -w 12 -l 6 fields.c pass: -w 12 -l 6 grammar.lsp pass: -w 12 -l 6 kennedy.xls pass: -w 12 -l 6 lcet10.txt pass: -w 12 -l 6 plrabn12.txt pass: -w 12 -l 6 ptt5 pass: -w 12 -l 6 sum pass: -w 12 -l 6 xargs.1 pass: -w 12 -l 7 alice29.txt pass: -w 12 -l 7 asyoulik.txt pass: -w 12 -l 7 cp.html pass: -w 12 -l 7 fields.c pass: -w 12 -l 7 grammar.lsp pass: -w 12 -l 7 kennedy.xls pass: -w 12 -l 7 lcet10.txt pass: -w 12 -l 7 plrabn12.txt pass: -w 12 -l 7 ptt5 pass: -w 12 -l 7 sum pass: -w 12 -l 7 xargs.1 pass: -w 12 -l 8 alice29.txt pass: -w 12 -l 8 asyoulik.txt pass: -w 12 -l 8 cp.html pass: -w 12 -l 8 fields.c pass: -w 12 -l 8 grammar.lsp pass: -w 12 -l 8 kennedy.xls pass: -w 12 -l 8 lcet10.txt pass: -w 12 -l 8 plrabn12.txt pass: -w 12 -l 8 ptt5 pass: -w 12 -l 8 sum pass: -w 12 -l 8 xargs.1 ==== Total compression: 11541.96% for 242 documents (avg. 47.69%) 14.40user 1.59system 0:15.07elapsed 106%CPU (0avgtext+0avgdata 4392maxresident)k 120inputs+175640outputs (21major+266723minor)pagefaults 0swaps |
It would be nice to compare heatshrink to another popular compression library like gzip, and that’s exactly what Scott Vokes in a blog post after he released the library in 2013.
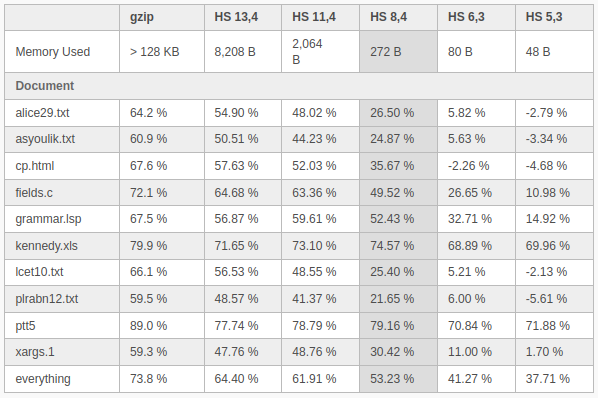
gzip has a better compression ratio in every case, but obviously uses a lot more RAM than heatshrink, and with over 128KB of RAM used not suitable for many microcontrollers. If you are using the compression library with the lower settings you may want to check if it’s not actually increasing the size as HS 6,3 and HS 5,3 options in the table above did have some of the compressed files larger than the original. Still, it’s a nice option to have, and I can see somebody made an Arduino library based on Heatshrink as well.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress



Considering the subject is lzw compressions, I guess it’s a good a time to mention encode.ru moved to encode.su.
Looks like we think similarly.
Thanks for sharing this! The compression ratios are very good! I compared with SLZ that I created for the same memory considerations reason, that produces a gzip-compatible output stream and that is particularly suitable for use in HTTP proxies and servers, and I need to use larger blocks to achieve the same ratio as HSS8,4 (gzip output format is not that efficient). However the permanent state remains fixed at 24 bytes. Interestingly the compression ratio for kennedy.xls is quite poor in my case (66%), I’ll have to check why, I suspect that many literals are emitted and that their encoding is not optimal.
One nice point here is the very small decompression code. Gzip is too complicated with huffman and is definitely not suitable for microcontrollers. However the decompression performance might be an important aspect (e.g. for boot time), and here, seeing half a second on a PC to emit only 16 MB looks particularly slow. Some algos like LZO and LZ4 come with extremely fast decompressors (typically 100 times faster) that remain quite small as well.
nice, didn’t know about this one.
Ooh, very clever name!
I wonder how big this will be on something really crap like an 8051? If the code did compile to something like 50 bytes it could be useful for squashing static data like USB descriptors etc.
No it’s not 50 bytes of code, it’s 50 bytes of state to have to be kept between subsequent calls to the compressor. The code is a bit larger. Also it will possibly be very slow on a 8051 because decompression is already 100 times slower than gunzip on a PC. But in order to decompress small code once at boot that might be totally fine.
*re-reads article* – 50 bytes of RAM .. mm
I’m writing a replacement for the CH341 on the breadbee with a CH552 to allow for serial and for programming blank flash (SoC has a secret flashing interface on the UART pins) so I can finally sell them without getting in copyright trouble. Very close to filling the flash. Compressing the USB descriptors with something might have helped if the code wasn’t bigger than the descriptors. 🙂
BTW it is Espruino not ESPruino. The name has nothing to do with ESP32/8266 chips. Esp comes from ECMAScript=Javascript. Even the Javascript standards are called ESx https://www.espruino.com/Features