
We are seeing a massive increase in resource-constraints for embedded devices due to a lack of mature software stacks. With the increase in open-source hardware, the available software support takes a considerable amount of time to develop AI/ML/DL applications. Some of the challenges faced today are that bare-metal devices do not have on-device memory management, and they do not have LLVM support. They are also hard to debug because of rigid programming and cross-compilation interfaces.
Due to this, “optimizing and deploying machine learning workloads to bare-metal devices today is difficult”. To tackle these challenges, there have been developments to support TVM, an open-source machine learning compiler framework for CPUs, GPUs, and machine learning accelerators, on these bare-metal devices, and Apache TVM is running an open-source foundation to make this easy. “µTVM is a component of TVM that brings broad framework support, powerful compiler middleware, and flexible autotuning and compilation capabilities to embedded platforms”.
TVM that features a microcontroller backend, is called uTVM (MicroTVM) which facilitates tensor programs on bare-metal devices which in turn enable auto-optimization via AutoTVM. This notably provides an alternative to TensorFlow Lite for microcontrollers.
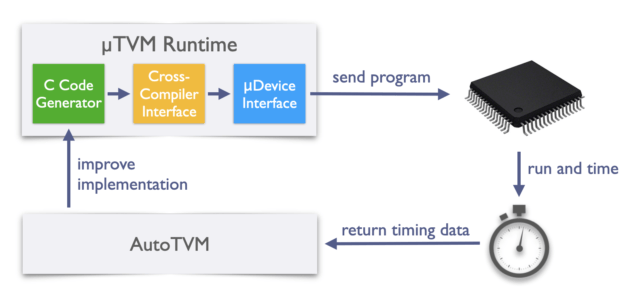
How do uTVM and AutoTVM work?
One of the examples demonstrated by OctoML uses an STM32F746ZG board connected to a desktop machine via a USB-JTAG port. The host computer runs OpenOCD, which allows JTAG connections and then enables the uTVM to control the board SoC using a device-agnostic TCP socket.
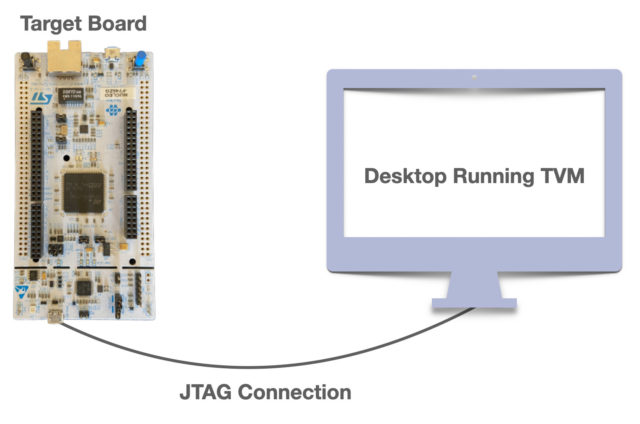
More details can be found on the Apache TVM website. The performance when compared to the hand-optimized library of ML kernels seems to give almost the same performance as CMSIS-NN.
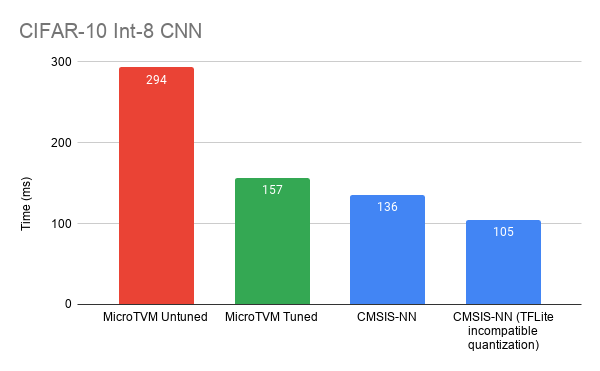
But the runtime is still an issue that isn’t suitable for model deployment yet since the model relies heavily on the host machine. So, AutoTVM comes into the picture as it runs the model on the target backend with random inputs.
“Lazy execution allows us to run the same operator many times without returning control to the host, so the communication cost is amortized over each run, and we can get a better idea of the performance profile.” For this, there is a need to make use of both flash memory and RAM.
According to OctoML, “MicroTVM for single-kernel optimization is ready today and is the choice for that use case. As we now build out self-hosted deployment support we hope you’re just as excited as we are to make µTVM the choice for model deployment as well. However, this isn’t just a spectator sport – remember: this is all open source! µTVM is still in its early days, so every individual can have a great deal of impact on its trajectory. Check out the TVM contributor’s guide if you’re interested in building with us or jump straight into the TVM forums to discuss ideas first.”
There have been several talks on uTVM for Bare Metal Devices.


Abhishek Jadhav is an engineering student, RISC-V Ambassador, freelance tech writer, and leader of the Open Hardware Developer Community.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress


