
When it comes to AI inference accelerators, NVIDIA has captured the market as drones, intelligent high-resolution sensors, network video recorders, portable medical devices, and other industrial IoT systems use NVIDIA Jetson Xavier NX. This might change as Flex Logix’s InferX X1 AI inference accelerator has been shown to outperform Jetson Xavier NX as well as Tesla T4.
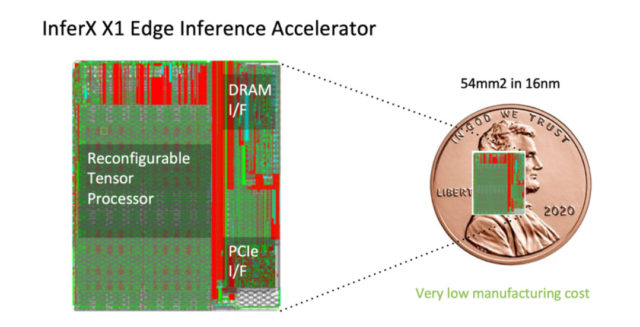
During the Linley Fall Conference 2020, Flex Logix showcased InferX X1 AI Inference Accelerator, its performance, and how it outperformed other edge inference chips. It is the most powerful edge inference coprocessor with high throughput, low latency, high accuracy, large model megapixels images, and small die for embedded computing devices at the edge. The estimated worst-case TDP (933MHz, YOLOv3) is 13.5W.
The coprocessor operates on the INT8 or BF16 precision over a batch size of 1 for minimum latency. The nnMAX Reconfigurable Tensor Processor accelerator engine exists in the edge inference coprocessor- InferX X1. The nnMAX Reconfigurable Tensor Processor is optimized for AI edge inference and is based on silicon-proven EFLX eFPGA technology. It provides data flow architecture, high-resolution utilization, low latency, high performance (at a batch size of 1), and low DRAM bandwidth. The accelerator engine is powerful for edge computing devices as it offers low-cost, low-power, and superior scalability.
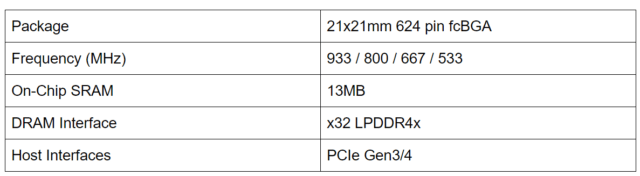
Specification
The chip has a 32-bit LPDDR4x DRAM with PCIe Gen 3/4 host interface. The host interface is a 4 lane configuration.
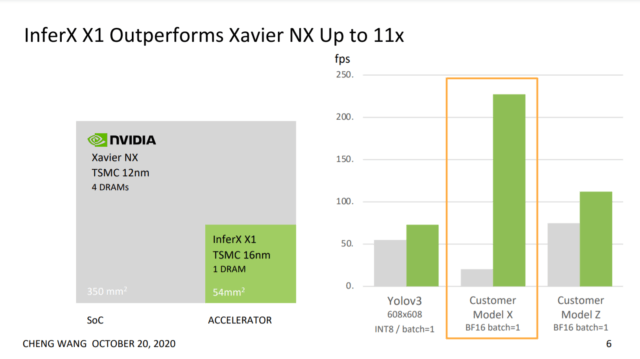
Performance
According to the comparative benchmarks posted by Flex Logix, the chip outperforms Jetson Xavier NX as well as Tesla T4. It exceeds the performance in every model tested (YOLOv3, customer Model X, and customer Model Z). The InferX X1 chip uses a 2×2 array of nnMAX 1-D TPUs with 13MB (on-chip SRAM) in a chip that in total is 54 mm2. Below we compare its performance on 2 real customer models (customer model X and customer model Z) and on YOLOv3.
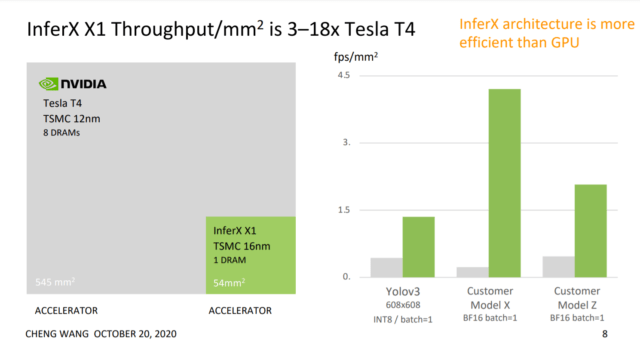
Availability and Cost
The availability of the InferX X1 edge inference accelerator:
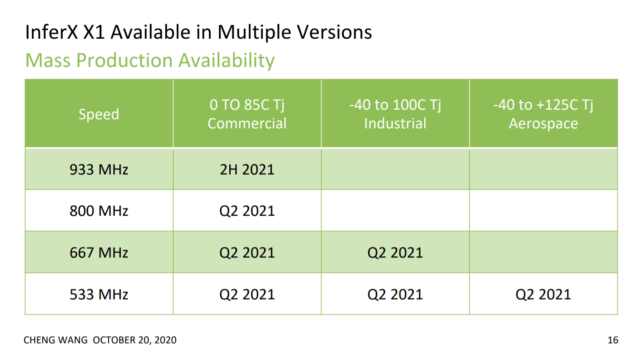
InferX beats Xavier NX Speed at a lower price and lower power. The pricing of InferX X1 can be seen in the table:

Conclusion
The AI benchmarks show the chip is very powerful over existing edge inference chips. It will be interesting to see ultimately how this performs in the market. We are certainly waiting for the PCIe/M.2 board products from the company. Flex Logix plans to officially announce those and provide details on October 28th at the Linley Fall Processor Conference.

For more information, please visit Flex Logix

Abhishek Jadhav is an engineering student, RISC-V Ambassador, freelance tech writer, and leader of the Open Hardware Developer Community.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress



Flex Logix, an eFPGA company, has stopped selling its InferX X1 AI accelerator chip, and will instead bring the architecture to market as licensable IP according to EETimes: https://www.eetimes.com/flex-logix-cancels-ai-chip-markets-ip-for-ai-and-dsp/