
I recently reviewed ODROID-H2 with Ubuntu 19.04, and noticed some errors messages in the kernel log of the Intel Celeron J4105 single board computer while running SBC-Bench benchmark:
|
1 2 3 4 5 6 7 8 9 |
[180422.405294] mce: [Hardware Error]: Machine check events logged [180425.656449] mce: [Hardware Error]: Machine check events logged [180483.582825] mce_notify_irq: 17 callbacks suppressed [180483.582827] mce: [Hardware Error]: Machine check events logged [180484.991484] mce: [Hardware Error]: Machine check events logged [180594.700684] mce_notify_irq: 13 callbacks suppressed [180594.700686] mce: [Hardware Error]: Machine check events logged [180858.202115] mce: [Hardware Error]: Machine check events logged [181178.047031] mce: [Hardware Error]: Machine check events logged |
I did not know what do make of those errors, but I was told I would get more details with mcelog which can be installed as follows:
|
1 |
sudo apt install mcelog |
There’s just one little problem: it’s not in Ubuntu 19.04 repository, and a bug report mentions mcelog is not deprecated, and remove from Ubuntu 18.04 Bionic onwards. Instead, we’re being told the mcelog package functionality has been replaced by rasdaemon.
But before looking into the utilities, let’s find out what Machine Check Exception (MCE) is all about from ArchLinux Wiki:
A machine check exception (MCE) is an error generated by the CPU when the CPU detects that a hardware error or failure has occurred.
Machine check exceptions (MCEs) can occur for a variety of reasons ranging from undesired or out-of-spec voltages from the power supply, from cosmic radiation flipping bits in memory DIMMs or the CPU, or from other miscellaneous faults, including faulty software triggering hardware errors.
Hardware error should probably be taken seriously. Let’s investigate how to run the tools. First, I try to install mcelog from Ubuntu 16.04:
|
1 2 |
wget http://archive.ubuntu.com/ubuntu/pool/universe/m/mcelog/mcelog_128+dfsg-1_amd64.deb sudo dpkg -i mcelog_128+dfsg-1_amd64.deb |
Oh good! It could install… Let’s run some commands:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
sudo mcelog [sudo] password for odroid: mcelog: Family 6 Model 7a CPU: only decoding architectural errors mcelog: warning: 32 bytes ignored in each record mcelog: consider an update odroid@ODROID-H2:~$ sudo mcelog --client Memory errors SOCKET 1 CHANNEL 5 DIMM 0 DMI_NAME "A1_DIMM0" DMI_LOCATION "A1_BANK0" corrected memory errors: 0 total 0 in 24h uncorrected memory errors: 0 total 0 in 24h SOCKET 1 CHANNEL 5 DIMM 1 DMI_NAME "A1_DIMM1" DMI_LOCATION "A1_BANK1" corrected memory errors: 0 total 0 in 24h uncorrected memory errors: 0 total 0 in 24h |
Nothing interesting shows up here, but the file /var/log/mcelog is now up, and we can see details about the errors:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
cat /var/log/mcelog mcelog: Family 6 Model 7a CPU: only decoding architectural errors Hardware event. This is not a software error. MCE 0 CPU 0 BANK 1 TSC bd2ee6710 TIME 1563095601 Sun Jul 14 16:13:21 2019 MCG status: MCi status: Corrected error Error enabled Threshold based error status: green MCA: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error STATUS 902000460082110a MCGSTATUS 0 MCGCAP c07 APICID 0 SOCKETID 0 CPUID Vendor Intel Family 6 Model 122 ... |
But let’s also try the recommended rasdaemon to see if we can get similar details.
Installation:
|
1 |
sudo apt install rasdaemon |
It looks like the service will not start automatically upon installation, so a reboot may be needed, or simply run the following command:
|
1 |
service rasdaemon start |
I ran a few commands and at first, it looked like some driver may be needed:
|
1 2 3 4 |
ras-mc-ctl --mainboard ras-mc-ctl: mainboard: HARDKERNEL model ODROID-H2 sudo ras-mc-ctl --status ras-mc-ctl: drivers not loaded. |
This should be related to EDAC drivers that are used for ECC memory according to a thread on Grokbase. Gemini Lake processors do not support ECC memory, so I probably don’t need it.
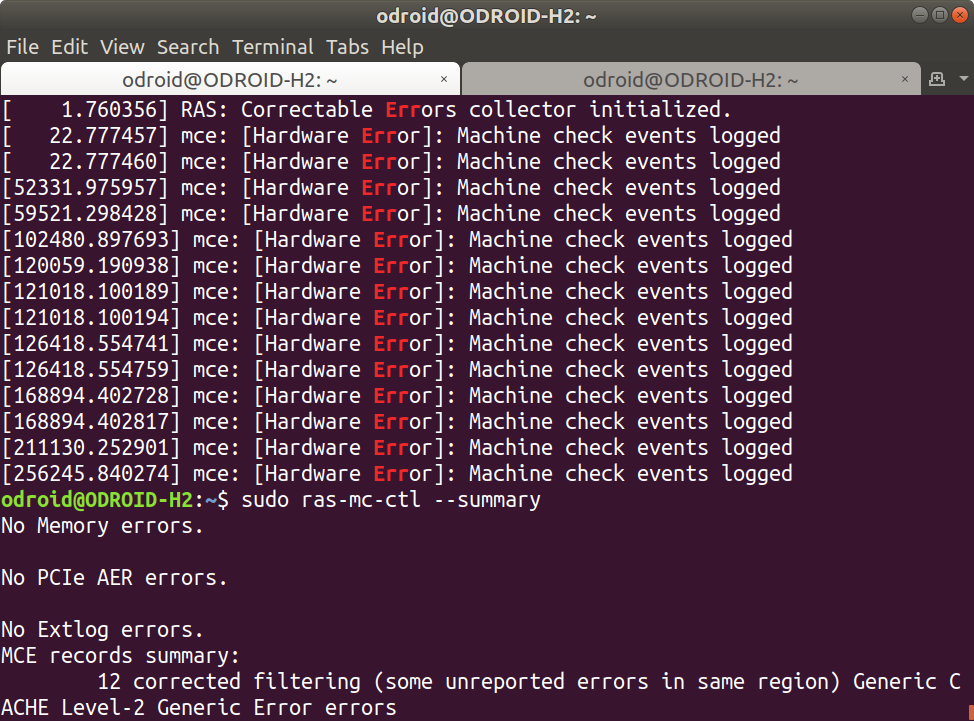
Running one more command to show the summary of errors, and we’re getting somewhere:
|
1 2 3 4 5 6 7 8 |
sudo ras-mc-ctl --summary No Memory errors. No PCIe AER errors. No Extlog errors. MCE records summary: 12 corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error errors |
12 corrected error related to the L2 cache. We can get the full details with the appropriate command:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
sudo ras-mc-ctl --errors No Memory errors. No PCIe AER errors. No Extlog errors. MCE events: 1 2019-07-15 20:41:09 +0700 error: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error, mcg mcgstatus=0, mci Corrected_error Error_enabled Threshold based error status: green, Large number of corrected cache errors. System operating, but might leadto uncorrected errors soon, mcgcap=0x00000c07, status=0x942000460082110a, addr=0x243e9f840, tsc=0x8b99a7f84108, walltime=0x5d2c8276, cpuid=0x000706a1, bank=0x00000001 2 2019-07-16 01:34:09 +0700 error: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error, mcg mcgstatus=0, mci Corrected_error Error_enabled Threshold based error status: green, Large number of corrected cache errors. System operating, but might leadto uncorrected errors soon, mcgcap=0x00000c07, status=0x942000460082110a, addr=0x24b9df840, tsc=0xa38afb430944, walltime=0x5d2cc722, cpuid=0x000706a1, bank=0x00000001 3 2019-07-16 01:50:08 +0700 error: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error, mcg mcgstatus=0, mci Corrected_error Error_enabled Threshold based error status: green, Large number of corrected cache errors. System operating, but might leadto uncorrected errors soon, mcgcap=0x00000c07, status=0x902000420082110a, tsc=0xa4d95741ee28, walltime=0x5d2ccae1, cpuid=0x000706a1, bank=0x00000001 4 2019-07-16 01:50:08 +0700 error: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error, mcg mcgstatus=0, mci Corrected_error Error_enabled Threshold based error status: green, Large number of corrected cache errors. System operating, but might leadto uncorrected errors soon, mcgcap=0x00000c07, status=0x902000420082110a, tsc=0xa4d957436320, walltime=0x5d2ccae1, cpuid=0x000706a1, bank=0x00000001 5 2019-07-16 01:50:08 +0700 error: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error, mcg mcgstatus=0, mci Corrected_error Error_enabled Threshold based error status: green, Large number of corrected cache errors. System operating, but might leadto uncorrected errors soon, mcgcap=0x00000c07, status=0x902000420082110a, tsc=0xa4d957451d82, walltime=0x5d2ccae1, cpuid=0x000706a1, bank=0x00000001 6 2019-07-16 01:50:08 +0700 error: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error, mcg mcgstatus=0, mci Corrected_error Error_enabled Threshold based error status: green, Large number of corrected cache errors. System operating, but might leadto uncorrected errors soon, mcgcap=0x00000c07, status=0x902000420082110a, tsc=0xa4d957456482, walltime=0x5d2ccae1, cpuid=0x000706a1, bank=0x00000001 7 2019-07-16 03:20:09 +0700 error: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error, mcg mcgstatus=0, mci Corrected_error Error_enabled Threshold based error status: green, Large number of corrected cache errors. System operating, but might leadto uncorrected errors soon, mcgcap=0x00000c07, status=0x902000400082110a, tsc=0xac3468f91976, walltime=0x5d2cdffa, cpuid=0x000706a1, bank=0x00000001 8 2019-07-16 03:20:09 +0700 error: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error, mcg mcgstatus=0, mci Corrected_error Error_enabled Threshold based error status: green, Large number of corrected cache errors. System operating, but might leadto uncorrected errors soon, mcgcap=0x00000c07, status=0x902000400082110a, tsc=0xac3468fb7a3a, walltime=0x5d2cdffa, cpuid=0x000706a1, bank=0x00000001 9 2019-07-16 15:08:09 +0700 error: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error, mcg mcgstatus=0, mci Corrected_error Error_enabled Threshold based error status: green, Large number of corrected cache errors. System operating, but might leadto uncorrected errors soon, mcgcap=0x00000c07, status=0x902000460082110a, tsc=0xe60f3181c782, walltime=0x5d2d85ea, cpuid=0x000706a1, bank=0x00000001 10 2019-07-16 15:08:09 +0700 error: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error, mcg mcgstatus=0, mci Corrected_error Error_enabled Threshold based error status: green, Large number of corrected cache errors. System operating, but might leadto uncorrected errors soon, mcgcap=0x00000c07, status=0x902000460082110a, tsc=0xe60f31852002, walltime=0x5d2d85ea, cpuid=0x000706a1, bank=0x00000001 11 2019-07-17 02:52:09 +0700 error: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error, mcg mcgstatus=0, mci Corrected_error Error_enabled Threshold based error status: green, Large number of corrected cache errors. System operating, but might leadto uncorrected errors soon, mcgcap=0x00000c07, status=0x942000460082110a, addr=0x249c5f840, tsc=0x11f964ae442b2, walltime=0x5d2e2aea, cpuid=0x000706a1, bank=0x00000001 12 2019-07-17 15:24:09 +0700 error: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error, mcg mcgstatus=0, mci Corrected_error Error_enabled Threshold based error status: green, Large number of corrected cache errors. System operating, but might leadto uncorrected errors soon, mcgcap=0x00000c07, status=0x902000440082110a, tsc=0x15d0984e5de54, walltime=0x5d2edb2a, cpuid=0x000706a1, bank=0x00000001 |
The status is green which means everything still works, but the utility reports a “large number of corrected cache errors”, and the “system (is) operating, but might lead to uncorrected errors soon” (See source code). It happens only a few times a day, and I’m not sure what can be done about the cache since it’s not something that can be changed as it’s embedded into the processor, maybe it’s just an issue with the processor I’m running. If somebody has an ODROID-H2 running, it may be useful to check out the kernel log with dmesg to see if you’ve got the same errors. If you do, please also indicate whether you have a board from the first batch (November 2018) or one of the new ODROID-H2 Rev B boards.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress



> the file /var/log/mcelog is now up
That’s how we monitor x86 commodity hardware: installing the
mcelogpackage, then defining a primitive rule watching the size of/var/log/mcelog. Once the size exceeds 0 you have a problem.As for the occurrences of these 2nd level cache errors: most probably they only occur once data is pumped through the CPU cores (e.g. running 7-zip or cpuminer as part of sbc-bench for example).
Thanks. I also got some errors today, while ODROID-H2 was mostly idle.
Could someone provide me with some help?
I use a small firewall with IPFire and get mce errors. How is this to be interpreted?
Might be worth also posting on Odroid H2 forum, issues or Ubuntu, maybe raise the number of board users reading this?
I’m not sure it’s important yet. After all, the board works just fine. I’ll contact Hardkernel.
Seem to be incompatible memory posts on Odroid forum. Could it be memory or hardware chips driver issues?
I’m using the DDR4 modules provided by Hardkernel, and there aren’t any memory errors, only L2 cache errors.
What the problem could potentially be is that the latest batch of Gemini Lake processors has some cache issues (TBC), which may explain why I have somewhat lower performance compared to earlier boards.
Cache issues in CPUs do happen. I’ve been hit many times with those in UltraSparc processors for example (and my U5 is sick again due to this for the second time by the way). I think modern CPUs use parity to better resist issues caused by heat and other random events. It’s “simple” enough to drop a line and re-read it when reading inconsistent data (it’s more difficult when changes are present but nothing prevents from re-reading the faulty word if it was not modified). In case that’s what you’re facing, there could be a corner case of locally-modified data which has changed before re-reading it and in this case it’s guaranteed data corruption. Better ask HK about it. If your board is the only one with this problem they might prefer to exchange it. I do have the exact same CPU on another board (asrock) and am not facing any such issues. I’ve just installed rasdaemon which noticed nothing either.
Some Intel chips go beyond parity checking and have ECC on L2. But I don’t know if this chip supports it, Intel doesn’t seem to document that openly.
Found a command to check that: sudo dmidecode and look for “Error Correction Type”. On my i7-8650U it shows L1D is parity protected, L2 is one-bit ECC and L3 it multi-bit ECC.
Yes I’m pretty sure that high-end chips do have ECC, but here we’re talking about an Atom basically. Well, marketingly speaking it’s a celeron 🙂
willy, you’re correct for DRAM ECC, here we’re talking about the internal caches 😉
Laurent, I was also speaking about internal caches 🙂 I’m sure I’ve seen it mentioned a few times in the past for Xeons and have some memories of seeing things like “L2 cache ECC” in some server BIOSes in the past. Note that it might have been quite old since my memory associates this to L2 not L3. Also IBM’s POWER8 and above definitely use ECC for L2 & L3.
Here’s the output of
sudo dmidecodeon ODROID-H2 for anyone interested.https://pastebin.cnx-software.com/?f3cdd3bc98d9ae09#6uAEW7Ab2csDUCNS1qjFG9a1z8UT5R65FaWC7U3aePvo
Error Correction Type: Single-bit ECC for L2 cache
The link doesn’t work here, it displays “privatebin is a minimalist …”.
It happens sometimes, and I have not figured out why yet: https://github.com/PrivateBin/PrivateBin/issues/453
If you are on desktop, can you try to press Ctrl+F5? If JavaScript is disabled this may not work at all.
In Android, data saver mode can create an issue: https://github.com/PrivateBin/PrivateBin/wiki/FAQ#how-to-make-privatebin-work-on-my-android-phone-with-data-saver-mode
Tried already, and again, but same result. It’s no big deal though, don’t worry 🙂
Hi there,
This is not normal. One error once in a couple months due to cosmic rays, that is normal.
You are being warned because at that rate there is something wrong with the hardware or too much EMI from another device.
> at that rate there is something wrong with the hardware
So far only ECCed (corrected) single bit flips in L2 cache. Harms slightly performance and will only be a real issue once two bits flip at the same time. While I wouldn’t trust such a CPU that much for the average use case a Gemini Lake box is taken (media center, desktop) this shouldn’t matter that much.
Physics is physics. You’re going to get bit flips in caches. Beta particles from C-14 decomposition. Beta particles from the Si itself, etc. Then there’s cosmic rays that you just can’t avoid as they’re everywhere. As transistors get smaller and smaller, Johnson–Nyquist noise becomes a bigger issue. The error may have even occured due to a transmission error on the chip–the right value may have been stored, but it got corrupted between the storage element and the ECC block.
As long as the ECC is catching single bit errors at a relatively low rate, there’s noting to worry about. If it’s seeing double bit errors, then it’s time to be concerned.
Sometimes there are 4 in the same second, this is far too much, something is busted in this machine, and its ability to recover from all the events you enumerated is affected by this existing one. The probability of two-bit *unrelated* errors remains very low. But if the hardware is defective, the probability of two-bit errors in the same cache line cannot be dismissed.
My SSD makes some noise. Maybe that’s the source of the problem. I’ll remove it to check out what happens.
That is usually coil whine and is not the issue.
I’d try setting a lower maximum clock and see if the problem goes away. I’d want to check if power regulation/supply isn’t deficient.
If the problem is the hardware, a torture test like Prime 95 will also make it much worse.
I don’t use an x86 MB/memory combo without first doing at least 24 hours of memtest86 and then Prime95 on torture test. That helps validate memroy, processor, power delivery, etc.
I used to run memtest86 for 24 hours, too. But then I got burned with broken RAM that memtest86 was not able to find no matter how long I tried. Didn’t know about Prime95 at that time but running sha1sum over all files in the filesystem repeatedly returned different hashes for the same files. And the problem went away by removing 2 of the 4 memory cards.
As such, I think running memtest86 is just waste of time. Prime95 / mprime -t is much better option. However, you need to manually adjust the RAM usage to cover all chips. If you want to test your whole system, run max load *at the same time* (e.g. if you have high end GPU, run 3D benchmarks, run fio random read and writes to all storage devices).
I’ve disconnected all SATA data and power cable, and the errors are still there. It seems even worse than the first time I ran sbc-bench.sh:
Before I ran sbc-bench.sh I had 924 errors logged, and after:
I’ll try to change the max frequency and see what happens.
I’ve gone to the BIOS and changed two settings:
ran sbc-bench again, and all MCE errors are gone:
> I’ve gone to the BIOS and changed two settings
And you lost around 1/3 of the CPU performance 🙂
Smells a bit like unstable high DVFS OPP…
Yeah, any of the modes be the cause of this unless they’re bugged. I agree with Kaiser it’s DVFS bug probably. Could also be something on the hardware design – like capacitors – which can’t handle higher current swings.
BTW, I once had an issue with a motherboard BIOS where it would have correctable and uncorrectable L1/L2 errors when doing light loads.
The board was initially K8 only but eventually supported Phenom 1 and 2.
Somewhere something broke, as the motherboard induced errors if I enabled frequency scaling on the K8 but worked fine with a Phenom II – which used a different version of C&Q.
K8 CPU worked fine if set at any fixed speed, just couldn’t change on demand. Prob was changing clocks too fast, without letting the VRM stabilize at the higher voltages first.
Have Odroid replied yet?
Yes:
We could have hoped better, like “given that yours shows problems we cannot reproduce it definitely indicates a hardware issue and a risk of accelerated aging, we’re going to replace it”. Their response is a bit disappointing.
For full context, it’s a review sample, and I did not pay for it. Hardkernel just sent the kit to me free of charge.
OK that’s understandable then. Still they’d better make some statements like “oh we know our early samples were not perfect” than let the doubt exist about their hardware.
I agree with Willy – most manufacturers would want the board back for further testing. Doesn’t give much confidence that they will do proper Q/A.
Thank you for reporting MCE problem on Gemini Lake. It helped me not to buy it. I already have MCE errors on Apollo Lake Asrock J3455-ITX and thought that problem will not show on Gemini Lake. Unfortunately it does not seam to be the case…
avra@falcon:~$ uname -a
Linux falcon 4.19.0-0.bpo.2-amd64 #1 SMP Debian 4.19.16-1~bpo9+1 (2019-02-07) x86_64 GNU/Linux
avra@falcon:~$ dmesg | grep microcode
dmesg: read kernel buffer failed: Operation not permitted
avra@falcon:~$ sudo dmesg | grep microcode
[sudo] password for avra:
[ 0.961770] mce: [Hardware Error]: PROCESSOR 0:506c9 TIME 1564253320 SOCKET 0 APIC 0 microcode 1e
[ 3.731218] microcode: sig=0x506c9, pf=0x1, revision=0x1e
[ 3.731754] microcode: Microcode Update Driver: v2.2.
avra@falcon:~$ sudo dmesg | grep mce
[ 0.935565] mce: CPU supports 7 MCE banks
[ 0.961475] mce: [Hardware Error]: Machine check events logged
[ 0.961569] mce: [Hardware Error]: CPU 0: Machine Check: 0 Bank 4: a600000000020408
[ 0.961673] mce: [Hardware Error]: TSC 0 ADDR fef135c0
[ 0.961770] mce: [Hardware Error]: PROCESSOR 0:506c9 TIME 1564253320 SOCKET 0 APIC 0 microcode 1e
I think it’s a matter of luck. Most processors won’t have this issue, but some will have.
Your problem looks a bit different. Does it cause you troubles or just output errors without actual user-facing issues?
This is an error in the processor. It could be induced by bad power or inappropriate clock speed. Other than that, it is likely a busted processor chip.
If you are just using the machine for benchmarking, who cares.
Otherwise, I would discard the board.
(I’m assuming that the processor is not socketted.)
The right way of thinking about ECC is as a life preserver. Your boat is sinking, but you can float long enough to get to another boat. You don’t use it to try to keep the old boat floating.
The “Drivers not loaded” message is a bit spurious. It just looks in /proc/modules for anything having edac in the name and assumes that is good, regardless of whether it is the right driver for your machine. If it doesn’t see anything, for example if the correct edac driver is built in to the kernel, then it reports that the driver isn’t loaded. So the message has nothing to do with MCE and may or may not be reporting the status of EDAC monitoring.