
In the x86 world, one operating system image can usually run on all hardware thanks to clearly defined instruction sets, hardware and software requirements. Arm provides most flexibility in terms of peripherals, while having a fixed set of intrusions for a given architecture (e.g. Armv8, Armv7…), and this lead to fragmentation, so that in the past you had to customize your software with board files and other tweaks, and provide one binary per board, leading to lots of fragmentation. With device trees, things improved a bit, but there are still few images that will run on multiple boards without modifications.
RISC-V provides even more flexibility that Arm since you can mess up with the instructions set with designers able to add or remove instructions as they see fit for their application. One can easily imagine how this can lead to a complete mess with binary code only running on a subset of RISC-V platforms, and lots of compiler options to build the code for a particular RISC-V SoC.

Brian Bailey, Technology Editor/EDA for Semiconductor Engineering, goes into details about the challenges of RISC-V compliance in details, and I’ll try to summarize the key points in this post.
Allen Baum, system architect at Esperanto Technologies and chair of the RISC-V Compliance Task Group explains:
RISC-V is an open-source standard ISA with exceptional modularity and extensibility. Anyone can build an implementation and there are no license fees, except for commercial use of the trademarks.
…
Implementers are free to add custom extensions to boost capabilities and performance, while at the same time don’t have to include features that aren’t needed
…
Unconstrained flexibility, however, can lead to incompatibilities that could fragment the customer base and eliminate the incentives for cooperative ecosystem development.
That defines the issue, especially RISC-V is not controlled by one or two companies in like Arm and x86 worlds. Multiple companies will be designing their own RISC-V products, so they’ll each have to make sure their implementation complies with the specification. That’s why the RISC-V Compliance Task Group is working on developing RISC-V compliance tests in order to define rules to ensure software compatibility.
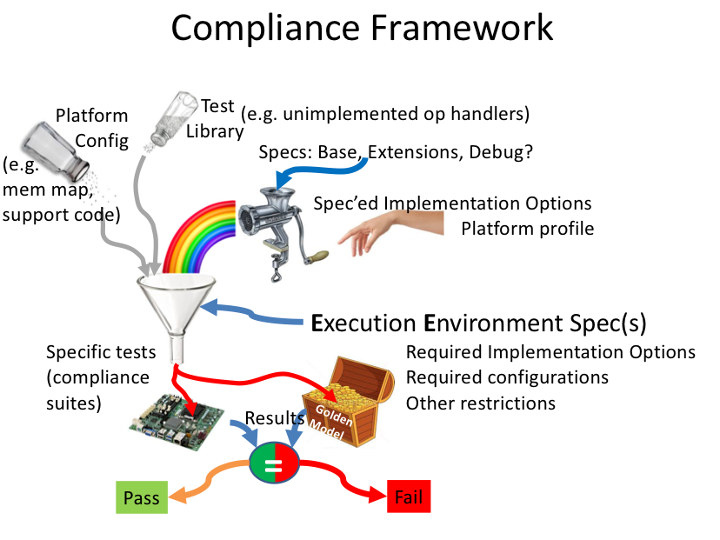
The RISC-V compliance framework is said to have three major elements
- A modular set of test suites that exercise all aspects of the ISA
- Golden reference signatures that define correct execution results
- Frameworks that select and configure appropriate test suites based on both platform requirements and claimed device capabilities
Running the tests will report fail/pass results for each test. The framework is only part of the verification process, as explained in the documentation:
The goal of compliance tests is to check whether the processor under development meets the open RISC-V standards or not. It is considered as non-functional testing meaning that it doesn’t substitute for design verification. This can be interpreted as testing to check all important aspects of the specification but without focusing on details, for example, on all possible values of instruction operands or all combinations of possible registers.
The result that compliance tests provide to the user is an assurance that the specification has been interpreted correctly and the design under test (DUT) can be declared as RISC-V compliant.
The tools are still work-in-progress, tests to be performed still need to be define, and will go beyond just ISA compliance, for example Tilelink cache-coherent interconnect fabric may have to be added to the compliance tests. Those tools will help making sure the processors compliant with basic RISC-V specifications, but it’s unclear how all RISC-V extensions that may be vendors specific will be handled, and some may even end up into the standard RISC-V compliance tests.
Thanks to Blu for the tip.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress



I’d go further and say that the one-image-runs-everywhere standardization in the x86 world was partially a result of the strictly-controlled ISA, but much more so of the fact the IBM AT prevailed as the dominant platform and was copied by everybody, providing a homogeneous basic device space for a kernel to work with. That was in the beginning, before things like ACPI matured. Also, keep in mind a kernel never goes full swing with an ISA — on the contrary, it tries to restrict itself to the most essential ISA subset that could get the job done. Most other ISAs, arm included, have never had such a homogeneity of the device platform, so device trees did come to address a huge gap there. BTW, DTs originate from AIM’s CHRP .
When speaking of ISA fragmentation, though, the bigger problem comes on the client-app side, as it’s client apps that take the lion share of CPU clocks. App developers have to make huge bets of ‘what is our target ISA for the next version?’ And there x86 is not any better than any of the other contemporary ISAs: amd64 has only *counts on fingers: SSE3, SSSE3, SSE4.1, SSE4.2, AVX, AVX2, AVX512* 7 SIMD extensions, not counting the still-born AMD extensions. That becomes a problem when your app is highly SIMD-reliant.
How the SIMD instructions, aren’t the ones to run automatically detected at runtime in most programs?
Usually the only automatic thing about SIMD versions are basic CRT routines like memcpy — everything else has to be deliberately accounted for in the code, either by manually providing versioned routines for runtime dispatch, or by shipping different-targets builds of the app, either way leading to an explosion of support options, if the developer is trying to be truly exhaustive. Which leads to most devs not bothering.
>either by manually providing versioned routines for runtime dispatch,
Or you do like Android did and provide a build system that can build multiple versions of the performance critical code into shared libraries and have the OS load the best version of the code at runtime.
In addition, most of the time when you care about a few cycles justifying to use SIMD instructions, you lose all your gains in the test and conditional jump required to check their presence!
>you lose all your gains in the test and conditional jump required to check their presence!
Why? You check once at startup and load your shared library/update your function pointer/patch your code once.
That still requires N x different versions of the shared library and N x the maintenance time.
Very often you only need one or two instructions in the middle of a loop which itself is in the middle of a more complex code, and having to have two version simply requires copy-paste of the function to exist using the two flavors. If you use high-level functions only (e.g. image compression) then I totally agree with you since in this case you share almost nothing and the various implementations are quite different. But that’s not always the case.
For our product we usually end up with different target builds for the several SIMD levels we support. We are trying to be maximally inclusive and it’s still a PITA.
>Also, keep in mind a kernel never goes full swing with an ISA — on the contrary,
>it tries to restrict itself to the most essential ISA subset that could get the job done.
Linux has SSE etc optimised code in many areas. Check your dmesg output.. even on ARM systems the kernel usually patches itself on boot to take advantage of instructions that not all ARM cores have.
Which are those many areas? memcpy, crypto/raid and?
>memcpy
Referenced in over 6000 files. Optimised versions of memset etc which have similar amounts of usage across the whole code base are in arch/x86/lib.
>crypto
Which is at least 20 different optimized cipher implementations for x86 alone.
> and?
perf is “isa aware”. There are optimised decompressors. Interrupt flow has some optimisation for different processor generations. The RNG stuff has support for processor specific RNG instructions AFAIK.
Due to how the asm includes work ISA specific code will be used all over the place.
In other words memcpy and crypto. Thanks.
and timers and other stuff you’ll ignore.
Ah yes, the ‘and stuff’ argument. As usual, you’re a source of wisdom.
oooo next you’ll be calling me kid again. Sorry I wondered on to your infinite wisdom lawn old man.
FYI just the perf subsystem in Linux totally invalidates what you wrote either way but if it makes you feel better being right you can have gold star from me. 😉
FYI, you switched your own argument from ‘SSE etc is used in many other areas of the kernel’ (hint: SSE etc SIMD isn’t used ‘in many other areas’, as the SIMD RF is subject to context-size kernel restrictions) to ‘bbbbut timers and perf are ISA aware!’ Sorry, kido, you don’t get any stars from me.
You:
>Also, keep in mind a kernel never goes full swing with an ISA — on the contrary
Me:
>SSE etc
On the SSE part:
One example of the kernel going “full swing”. One example means it’s not never. On the contrary there are multiple implementations of multiple ciphers for different SIMD extensions. Then there are multiple implementations of XOR for different SIMD extensions.
You might not consider them to be important or significant but they are there. Optimisations of things like memcpy, io access macros etc are important even if they are small because almost all of the rest of the code is combinations of calls to those functions/macros. A small optimisation that delivers a lot of value is a good thing isn’t it?
FYI I don’t think memcpy actually is optimised for any of the SIMD extensions.
On the etc part:
“etc” meaning things that aren’t SSE and from the context would be things that “go full swing with the ISA”. Lets distil that down to “ISA specific optimisations that aren’t necessary make it work” i.e. not the lowest common denominator for an arch.
Well those exist all over the place and you can see that for yourself by looking in arch/x86/lib and others and seeing there are multiple places that have hand optimised assembly and runtime detection of specific features.
For ARM the kernel patches div/mul and some userland stuff like gettime on boot. Again examples of specific ISA optimisations that aren’t technically required.
>SSE etc SIMD isn’t used ‘in many other areas’,
>as the SIMD RF is subject to context-size kernel restrictions)
It doesn’t matter how many areas SSE is used in. If it’s used in one area or one line then your statement is false. Obviously it’s not used in places that make no sense or it can’t be used.
>to ‘bbbbut timers and perf are ISA aware!’
perf might actually be useful to you as it is so aware of the ISA that you can use it to work out if your SIMD and other optimisations actually have any benefit. The perf subsystem has a lot of very ISA specific stuff in it so there’s so even if the above wasn’t true your statement would still be wrong.
bbbbut I’m going to make binary statement and then when presented with one example that negates my binary statement act like a baby and say bbbbut that doesn’t count because I say so.
>Sorry, kido, you don’t get any stars from me.
To be honest a kid getting stars from a random old guy would be pretty weird so I’m thankful for that.
> One example of the kernel going “full swing”. One example means it’s not never.
Erm, a full-swing ISA would be every single extension of the ISA circa the day of application. So unless you can demonstrate how the kernel as of today uses every single amd64 extension (that extends way beyond AXV2 and AES-NI, and includes things like AVX512) — yes, strictly speaking a kernel _never_ goes full swing. For a bunch of reasons, some of which we’ll discuss below.
But perhaps you could’ve asked for a clarification of ‘never goes full swing’ first? In which case I’d have told you that by that I meant ‘refrains from using ISA features in places where it would otherwise make sense due to a bunch of kernel-specific restrictions’. But no, you went ‘Aha, he said never! I know of a counter-example where the kernel uses ISA beyond the base amd64, so I’ll unleash my petulant self now!’
After I clearly told you I’m aware of where the kernel uses SIMD, you went on to explain how good those uses are, which I never argued in the first place. Petulant arguing for the sake of arguing.
> It doesn’t matter how many areas SSE is used in. If it’s used in one area or one line then your statement is false. Obviously it’s not used in places that make no sense or it can’t be used.
Obviously it’s not used in places where it can’t be used.. Obviously.
So if it makes sense to use some extension in some kernel code, but still it cannot be used there, then what — what kind of star do you count that as?
> To be honest a kid getting stars from a random old guy would be pretty weird so I’m thankful for that.
Sure, be my guest, stars or no stars, I’m enjoying your ramblings nevertheless.
“these goal posts were made for moving and that’s just what they’ll do”
I remember the IBM clone days and WinChip, Cyrix, Amd, intel etc days. Where software compatibility mattered.
The best way to stop fragmentation is simply to put a very high licence fee for non standard meeting designs, with no licence fee for those designs that meet the standard. Also only allow design that meet the standard the right to call their design a RISC-V chip.
You cannot be an all-inclusive free ISA *and* put a high license fee for custom designs — the two philosophies are mutually-exclusive. RISC-V have already chosen their path. Now they have to provide the ‘details’ and make sure the chosen path is viable for commercial hw and sw vendors alike. In this respect RV32G and RV64G are considered as good sets to standardize upon, but I think RV64GV would be even better..
You cannot be an ISA without some significant method of standardization.
Otherwise, you’re just providing a quicker path to proprietary, non-ISA designs.
No, it’s software availability which makes the ISA : when everything is available for a given ISA, if some extensions are not used, nobody will implement them because they become useless. And there is a high incentive for adopting what works out of the box.
The BIOS services are what made PCs succeed. Here if a rich boot loader was provided by default for a platform, allowing easy boot from various devices and switching between images + easy image updates from the BL itself, it would certainly be widely adopted. If that BL required, say, crypto extensions to validate an image’s integrity, you can be sure that everyone would implement them just to benefit from this nice BL which makes the end user’s experience way better. It’s as simple as this.
I think your last sentence is the best approach.
If it’s possible to make changes, someone can and will do it — either for fun or for profit. Lots of people don’t/won’t care about compatibility.
The trademark is the only available method to offer compatibility to those who care about it.
AFAIK the RV Foundation already does, or plans to do the right-to-brand compliance testing. So it’s not about the lack of methods for standardization — yes, those normally take comprehensive compliance suits and golden standards. It’s more about *what* should be standardized. As of now RISC-V is a large combination of extensions, and certifying against some of those for the right to bear the RISC-V logo means little. Is an RV64I-plus-a-metric-ton-of-proprietary-extensions still an RV64I? What if some of those extensions are non-orthogonal to the base set (example: x87 vs scalar SSE)? How strongly is the G set intended as an app-level base ISA — strongly/weakly/not-at-all? Shouldn’t an app-level ISA include the vector extension as well, given how all contemporary app-level ISAs have a SIMD out of the box? These are things that still stand discussion and which directly affect the plans of hw and sw vendors.
I wish they could also standardize what needs to be done in term of platform definition to have “one kernel to rule them all” like in x86 (and unlike arm), e.g. guarantee that any compliant device will have onboard permanent >256kB storage to store the bootloader+DT at a defined address…
Indeed, DTs need to be there from the start, no need to repeat the mistakes of other ISA vendors.
As I had to learn in the ARM world DTBs are non standard. Every new Kernel, even every patch can require a new or at least adjusted DTB…
Then Linux chases the DTS through a whole plethora of preprocessors, you can’t just use DTC on those without the full fledged Linux build system.
>I wish they could also standardize what needs to be done in term of platform definition to have
>“one kernel to rule them all” like in x86 (and unlike arm),
For Cortex A and better you should be able to boot a single kernel on any machine. Getting Linux running to the point it’ll run busybox on a totally new Cortex A machine is just a case of a few lines in the kernel source to register a new machine type and a device tree that contains at least the uart, arch timer and gic. (Usually easier said than done..)
The problem is after the basic stuff everything else is a horrific mess in most cases. Even when you have only standard IP blocks like off the shelf USB and ethernet controllers how they are actually wired to the processor isn’t standardised and in a lot of ways isn’t sane.
For example I worked on something recently that has a standard emac block from cadence that has been supported by Linux for ages now. You’d think you could just stick the memory address into your device tree and forget about it but in this SoC the vendor decided to wire it up so there each 16 bit register is 32 bit aligned so that driver has to have yet another hack added to make it work for that machine. Most people don’t want that code so it’ll be a compile time option but that means you now have a driver that might not actually work even though your device tree refers to it.
Almost ever driver for some standard IP block has weird hacks and quirks to it work on different machines so if you want a kernel that boots on any Cortex A7 machine you don’t just have a bunch of driver modules like you would on X86. You also have a bunch of machine specific crap and device tree linkage to turn the required crap on.
In other words, open source hardware works the same as open source software.
How easy is it to build a significant app that will run on any version of Linux without modification?
The good thing about open source is that anyone can modify it. The bad thing about open source is that lots of people modify it. It turns out that the biggest selling point is also the biggest drawback.
You do like Windows apps do and ship everything with the application. Be that static linking, shipping all the shared libraries, providing a docker image etc. How you do that without violating all the different licenses is another question though.