
Nick Smith has been messing around with clusters made of Arm boards for several years starting with Raspberry Pi boards, including a 5-node RPI 3 cluster, before moving to other boards like Orange Pi 2E, Pine A64+, or NanoPC-T3.
His latest design is based on twelve NanoPi Fire3 boards with 8 cores each, bringing the total number of cores to 96. The platform may not be really useful for actual HPC applications due to limited power and memory, but can still be relied upon for education and development, especially it’s easily portable. Nick also made some interesting points and discoveries.

It’s pretty with shiny blinking LEDs, and what looks like proper cooling, and the cluster can deliver 60,000 MFLOPS with Linpack which places it in the top 250 faster computers in the world! That’s provided we travel back in time to year 2000 through 🙂 By today’s standard, it would be rather slow, but that’s an interesting historical fact.
Nick also compared the price of NanoPi Fire3 and Raspberry Pi 3 in the UK, and with shipping, VAT, and duties (actual none needed) both boards are about the same price (£34.30 vs £33.59), but based on his benchmark, NanoPi Fire 3 is over 6 times faster.
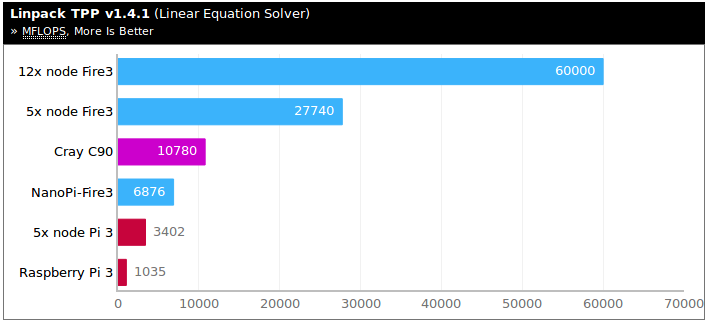 Something is not quite normal here. Both boards come with Cortex A53 cores with RPI 3 equipped with the Broadcom BCM2737 quad core processor @ 1.2 GHz, and NanoPi Fire3 with a Samsung S5P6818 octa core processor @ 1.4 GHz. The difference in hardware means we should expect 2 x (1.4/1.2) = 2.3 times better performance from Linpack for a single board. He’s probably using Raspbian (32-bit) on RPi 3, and possibly a 64-bit OS on Fire3, so that would add another ~30% extra performance to the total, or around 3 times faster. So there must be some other explanations like cache size, different compiler flags, or so on.
Something is not quite normal here. Both boards come with Cortex A53 cores with RPI 3 equipped with the Broadcom BCM2737 quad core processor @ 1.2 GHz, and NanoPi Fire3 with a Samsung S5P6818 octa core processor @ 1.4 GHz. The difference in hardware means we should expect 2 x (1.4/1.2) = 2.3 times better performance from Linpack for a single board. He’s probably using Raspbian (32-bit) on RPi 3, and possibly a 64-bit OS on Fire3, so that would add another ~30% extra performance to the total, or around 3 times faster. So there must be some other explanations like cache size, different compiler flags, or so on.
When it comes to multi-board performance, one should however expect scaling for the Raspberry Pi with its Fast Ethernet connection not to perform as well as on GbE ports equipped NanoPi Fire3 cluster, and that’s exactly the case here:
- 5x node Pi 3 vs single Raspberry Pi 3: 3.28x better performance
- 5x node Fire 3 vs single NanoPi Fire3: 4.06x better performance
It’s also worth noting in that particular benchmark, a single NanoPi FIre3 is twice as fast as 5 Pi 3 boards.
Both boards consume about the same amount of power, although NanoPi Fire3 a bit more, which results in Fire3 being 5.8x more power efficient than RPi3 in Linpack benchmark.
The whole setup is open and you can download DXF / SVG files for the laser but case, as well as get the list of parts in the aforelinked blog post. A selection of fans is also provided with different RPM and sizes, and performance test results (CPU throttling or not). The total cost for the setup with all 12 NanoPi board and shipping is £543.27 ($720 US).
If you’re interested in tutorials about running distributed software on NanoPi Fire3 cluster, you may want to check out to Nick’s website from time to time, as he plans to write two such tutorials namely “Cryptocurrency mining on an Arm supercomputer” in Q3 2018, and “Deep Learning AI on an Arm supercomputer” in Q4 2018.
Via Worksonarm

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress



I’m not surprised to see such incentives. The NanoPI Fire3 is very well designed to build clusters, and it currently achieves the highest performance-to-price ratio you can find. I’m hesitating building one such cluster just for fun but I wouldn’t have any use for it. I thought about using the micro-USB to connect boards through a USB hub to even save a switch, or daisy-chaining the boards (USB to micro-USB), for the occasional applications that don’t require a fast network connectivity (I think it’s the case for cryptocurrency mining as mentioned by the guy above). I don’t think this will be enough for compiling however, given that I’m seeing about 500 Mbps of LZO-compressed traffic on my 4-board MiQi farm.
> Something is not quite normal here.
The Raspberry Pi numbers smell like undervoltage (the primary operating system ThreadX running on the VC4 immediately downclocks the ARM cores to 600 MHz when input voltage drops below 4.65V while Linux still thinks it would run at 1200 MHz — the RPi Trading clowns funnily even defend this constant cheating).
So in case he used the shitty Micro USB connector to power the board the results are understandable. On every RPi it’s important to always run the following code in parallel while benchmarking since the RPi folks decided to cheat on their users by letting the Linux kernel report bogus clockspeeds:
Asides of that those benchmark scores are just the usual ‘numbers without meaning’. Running ‘apt install hpcc’ is BS since Linpack is not about running code but solving a problem. Especially given that software on the RPi is still compiled for ARMv6. No one interested in cluster computing will run such inefficient code.
The ‘official Linpack’ benchmark numbers with Raspbian for the RPi 3 and 3+ are laughable 200 Mflops, Nick achieves 1 Gflop while a real benchmark will show +6 Gflops on the RPi 3 and 12.5 Gflops on NanoPi M3 (and the successor Fire3 since it’s all only about the SoC which is the same)
See https://www.raspberrypi.org/forums/viewtopic.php?t=208167 (and search for ‘ejolson linpack site:armbian.com’ to get the correct numbers for NanoPi Fire3/M3 — there you can also see real network numbers –> ~925 Mbits/sec in both directions and not just 800)
I suspect he’s a non-rpi board fanboy. Rpi3B+ is among the fastest SBCs. Perfect for cluster. The new gigabit LAN even multiplies the interconnection bandwidth, which is important for fine grained parallel algorithms.
> Rpi3B+ is among the fastest SBCs. Perfect for cluster. The new gigabit LAN even multiplies the interconnection bandwidth
Are you paid by RPi Trading or an employee there? Or just not connected to reality?
> Are you paid by RPi Trading or an employee there? Or just not connected to reality?
I don’t think he ever had one in his hand to say something this funny, he probably only knows someone who owns one and who said how great it was. Saying this in front of performance reports debunking his claim is quite brave though 🙂
>Rpi3B+ is among the fastest SBC
.. are you smoking weed ?
I would expect that ODROID-MC1(https://www.hardkernel.com/main/products/prdt_info.php?g_code=G151794765828) as better variant
in my benchmarks one big ARM core has same speed as 3 small cores if I use NEON
so 1x Cortex A15 has same speed as 2-3xCortex A53
> in my benchmarks one big ARM core has same speed as 3 small cores if I use NEON
Are you comparing the A15 with A7 now? Or with A53? Asking since the only two benchmarks I used in the past that make heavy use of NEON perform way better on an A53 compared to an A7 at the same clockspeed: https://github.com/longsleep/build-pine64-image/pull/3#issuecomment-196267397
Found my cpuminer numbers for ODROID-XU4 (same as MC1): ‘When forced to run on the little cores cpuminer scores 2.27 khash/s, running on the big cores it starts with 8.23 khash/s’. A15 clocked at 2.0 GHz and immediately throttling down, the A7 cores ran at 1.4 GHz. As a comparison RK3328 numbers with 4xA53 also at 1.4 GHz: 3.95 kH/s with Libre Computer Renegade (DDR4) and 3.88 kH/s with Rock64 (DDR3)
ODROID-MC1 has nice heat sink, so it always run without problem on 2GHz when you use just big cores
It might not be a barn burner, but it’s still rather fast, if you put this into the proper perspective.
“Top 250 computers,” from 18 years ago…which would be an enormous room filled with hardware then. It fits in a shoebox, guys and consumes a teacupful of power in comparison.
It’s compelling fast enough to tinker with and experiment on real things and learn.
> It’s compelling fast enough to tinker with and experiment on real things and learn
Yes, NanoPi Fire3 is really great for such stuff!
And we should keep in mind that it’s not ‘60,000 MFLOPS with Linpack’ this cluster achieves but it’s 150,000 MFLOPS instead (a single NanoPi Fire3 scores 12.5 GFLOPS when benchmarked properly and MPI should scale linearly with such a setup).