
Arm servers are already deployed in some datacenters, but they are pretty new compared to their Intel counterparts, so at this stage software may not always be optimized as well on Arm as on Intel.
Vlad Krasnow working for Cloudflare found one of those unoptimized cases when testing out Jpegtran – a utility performing lossless transformation of JPEG files – on one of their Xeon Silver 4116 Server:
|
1 2 3 4 5 |
vlad@xeon:~$ time ./jpegtran -outfile /dev/null -progressive -optimise -copy none test.jpg real 0m2.305s user 0m2.059s sys 0m0.252s |
and comparing it to one based on Qualcomm Centriq 2400 Arm SoC:
|
1 2 3 4 5 |
vlad@arm:~$ time ./jpegtran -outfile /dev/null -progressive -optimise -copy none test.jpg real 0m8.654s user 0m8.433s sys 0m0.225s |
Nearly four times slower on a single core. Not so good, as the company aims for at least 50% of the performance since the Arm processor has double the number of cores.
Vlad did some optimization on The Intel processor using SSE instructions before, so he decided to look into optimization the Arm code with NEON instructions instead.
First step was to check which functions may slowdown the process the most using perf:
|
1 2 3 4 |
perf record ./jpegtran -outfile /dev/null -progressive -optimise -copy none test.jpeg perf report 71.24% lt-jpegtran libjpeg.so.9.1.0 [.] encode_mcu_AC_refine 15.24% lt-jpegtran libjpeg.so.9.1.0 [.] encode_mcu_AC_first |
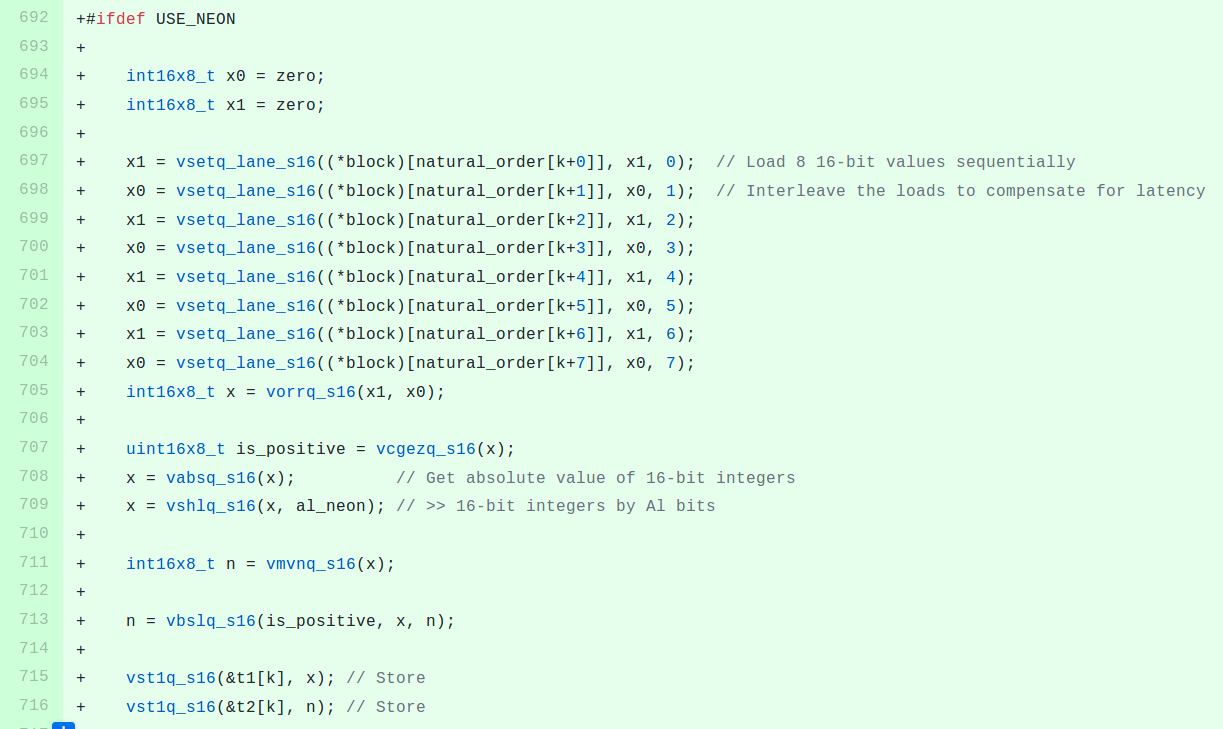
encode_mcu_AC_refine and encode_mcu_AC_first are the main culprits. He first optimized encode_mcu_AC_refine comprise of two loops with NEON instructions (Check the post on Cloudflare for technical details, or check the source on Github), which ended up boosting the performance per over two times:
|
1 2 3 4 5 |
vlad@arm:~$ time ./jpegtran -outfile /dev/null -progressive -optimise -copy none test.jpg real 0m4.008s user 0m3.770s sys 0m0.241s |
He matches his requirements of at least 50% performance of the Intel Xeon processor, but after optimization of the second function (encode_mcu_AC_first) plus the use of some NEON instructions with no equivalent in SSE such as vqtbl4q_u8 (TBL for 4 register) using assembly languages since the compiler would not generate optimal, he managed to transform the test image in just 2.756 seconds, ever closer to the 2.305 seconds achieved on the Intel Xeon.
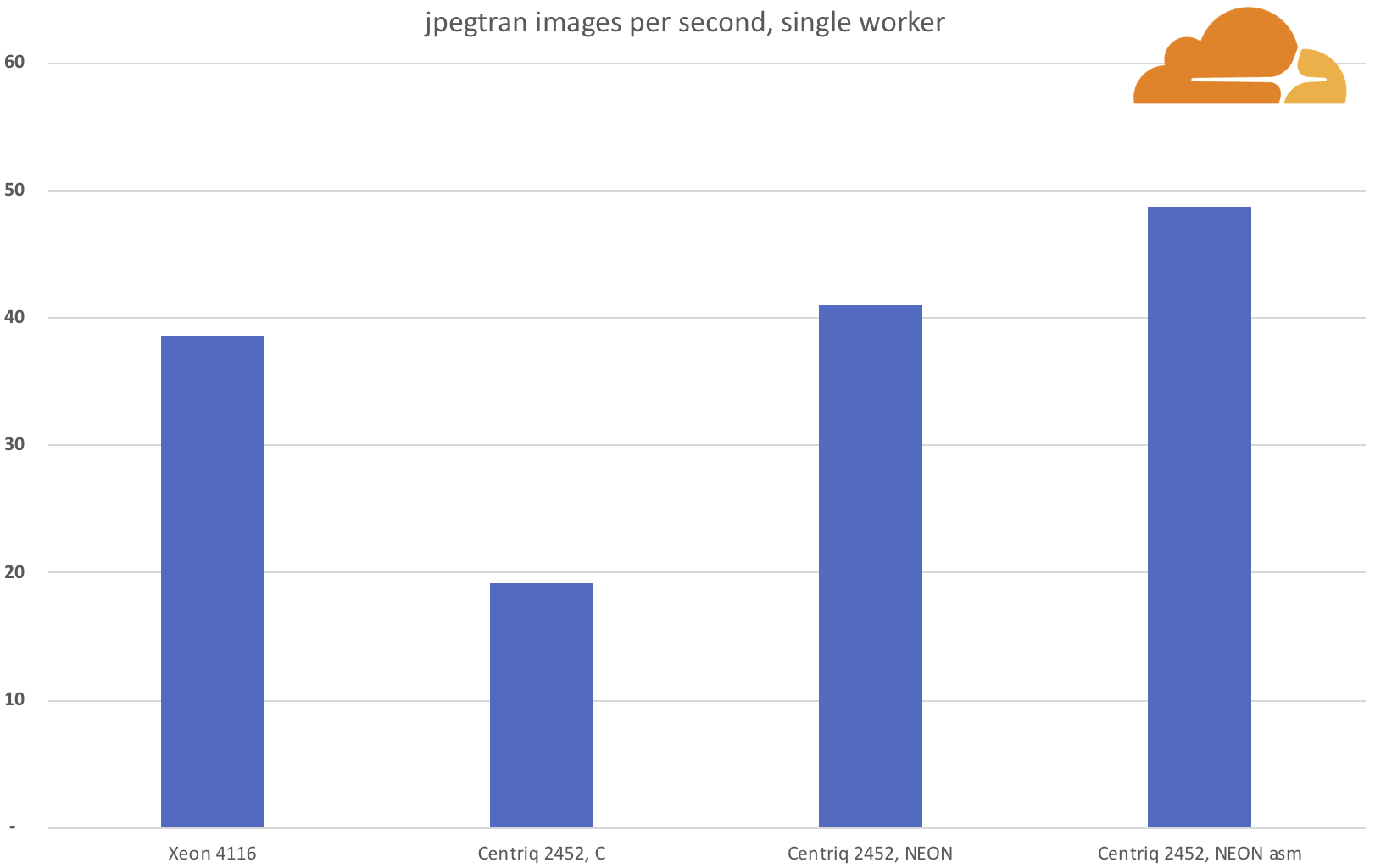
The final two charts compare the performance of the various stage of optimizations on set of 34,159 images, and here the Qualcomm processor is faster than the Intel Xeon with a single worker handling close to 50 images per second, against close to 40 images per second.
While scaling to more workers there’s still a slightly performance advantage for the Centriq processor, but what’s really impressive is that it is achieved at a much lower power consumption.
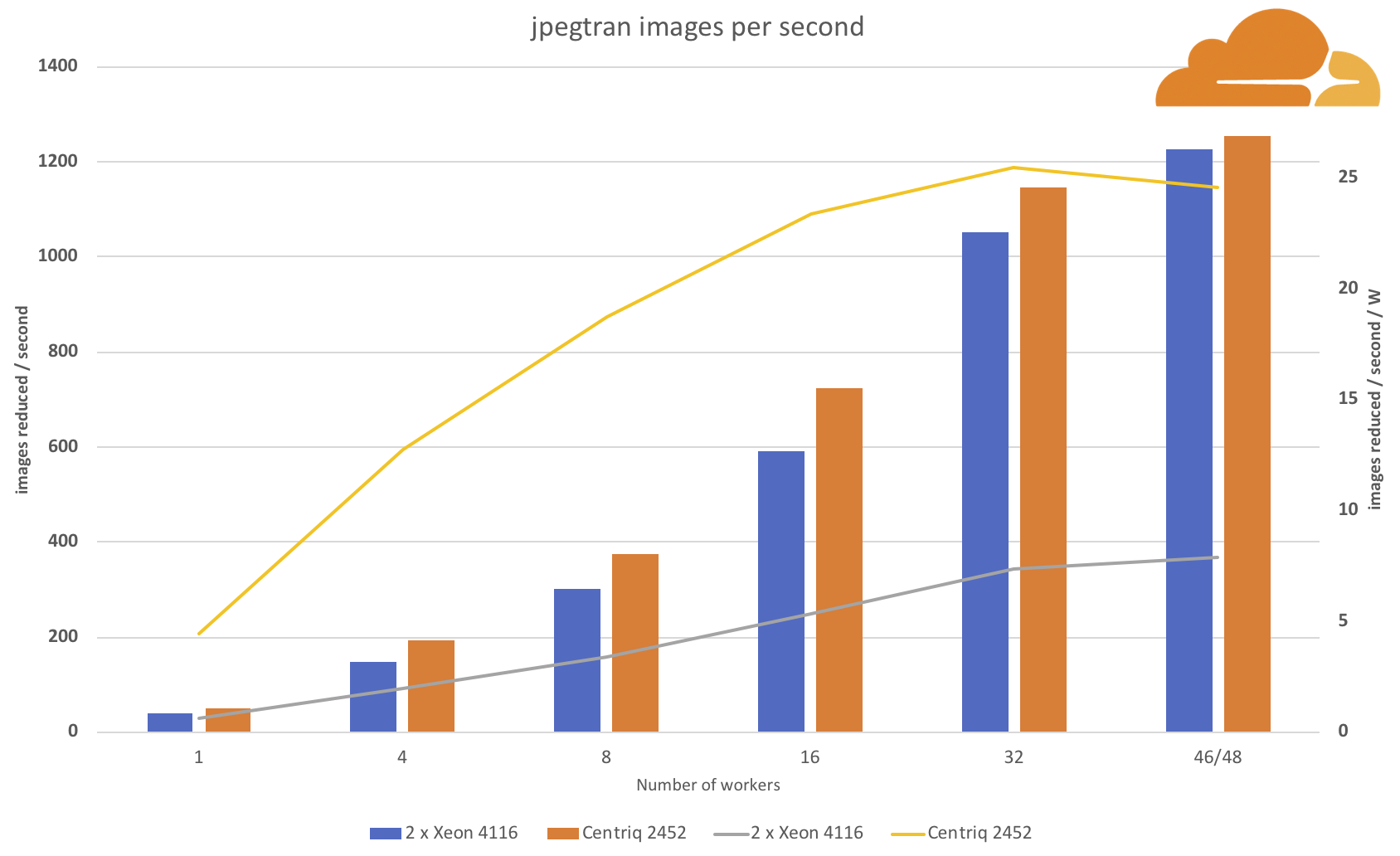
When using all available cores/threads, the Arm processor can “reduce” around 24 images per second with one watt, while two Intel Xeon processors can only manage 10 images per second with one watt.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress



Not surprised at all. When you look at the NEON instruction set, it looks much better thought than SSE, which possibly inherits a lot from older solutions like MMX. I noticed various generic single-instruction operations in NEON that could only be achieved with 3 or 4 operations with SSE. I seem to remember you cannot rotate in SSE for example.
Yep, we’ll be seeing more and more such cases in the future. ISAs matter, and while armv8 is not without its own gotchas, it’s very clearly the better thought out SIMD ISA.
It was some cool work. Great to see how a few lines can make such a huge boost to a library used by basically everyone. It’d have been nice to have seen what the compiler output was for in comparison – and explore if there is a way to reorganize the code to “coerce” the compiler to output something similar
The few times I’ve had to do similar things – I usually work by tweaking the code to give me the desired compiler output and I really try to avoid inline assembly.
Everybody tries to avoid inline assembly but compilers sometimes leave you no choice.
“Coercing” the compiler is usually not a good idea. Modern compilers take a lot of conditions into consideration when determining the final instructions they will generate and if any of those conditions change your crafted solution may stop behaving as expected. For example if have a function compute_dct() for use in the jpeg library and that function is inlined the final code it generates in one inline instance can be different from the code it generates in another instance because of the code before or after the call. Beyond that even upgrading the compiler or targeting a different architecture in the same family (e.g. skylake instead of broadwell) can cause the compiler to order the instructions different even if you limit it to the same instruction set (compiler takes into account cache and pipeline sizes among other things). As @blu said, sometimes you have no choice.
You have a good point – but but most of these problems (like forcing inlining) can be solved by constraining the compiler with compiler extensions (which kinda tie you to a compiler…. but it’s a limitation of C/C++). However.. autovectorization maybe isn’t one of them
The fact that behavior changes btw architectures is a potential plus. While the compiler can be very dumb and need hand holding, it can also do some very clever things you never thought of (esp btw. architectures) b/c it generally knows a lot more about the ISA than you. But maybe you’re right and it’s best not to gamble on the compiler
The King is dead, long live the King!