
Espressif Systems have been working on audio applications like Smart Speakers based on ESP32 WiSoC with hardware development kits like ESP32-LyraTD-MSC Audio Mic HDK, and I could test it with Baidu DuerOS using Mandarin language.
However, at the time (February 2018), there was not much else that could be done with the hardware kit, since no corresponding ESP32 audio software development kit had been made available. This has now changes since Espressif has just released ESP-ADF Audio Development Framework on Github.
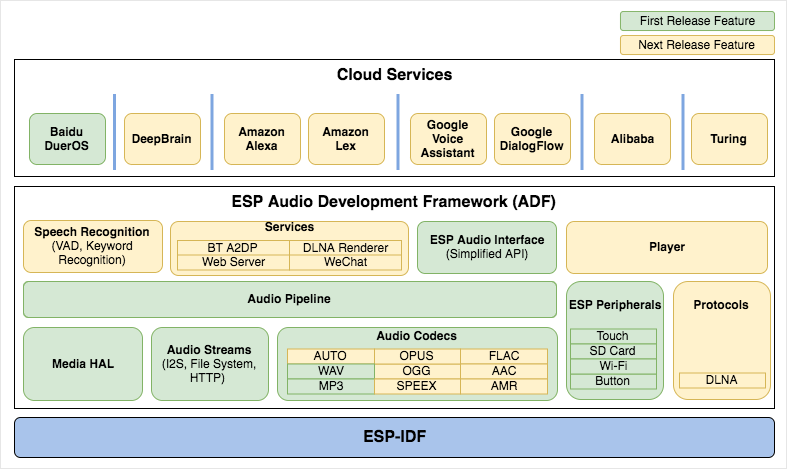 The framework will support the development of audio applications for the Espressif Systems ESP32 chip such as:
The framework will support the development of audio applications for the Espressif Systems ESP32 chip such as:
- Music player or recorder handling MP3, AAC, WAV, OGG, AMR, SPEEX … audio formats
- Play music from network (HTTP), storage (SD card), Bluetooth A2DP/HFP
- Integration with Media services such as DLNA, Wechat, etc..
- Internet Radio
- Voice recognition and integration with voice services such as Alexa, DuerOS, Google Assistant
As we can see from the diagram above, the first release supports Baidu DuerOS, WAV and MP3 audio, and ESP audio interface. The company will keep working on the framework to add more Cloud Services (DeepBrain, Alexa, Assistant, Alibaba…), Bluetooth support, DLNA support, and more audio codecs.

While several ESP32 boards will eventually be supported, there’s no documentation specific to ESP32-LyraTD-MSC “round” board yet, and instead a Getting Started Guide has been published for ESP32-LyRaT V4 board pictured above.
You’ll need to install ESP-IDF (Espressif IoT Development Framework) before using ESP-ADF, and to learn more details you may want to read the online documentation. ESP-ADF is released under ESPRESSIF MIT License.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress



That is pretty nice. I am looking at the board and it looks like is having everything from SD card to battery charger. It looks very promising. I hope that they will ship some prototypes like they did with ESP32 so we can get an early look. I would love to integrate it with Amazon, I have experience with this.
I understand that those privacy-infringing cloud-based voice spying services are all the hype right now, but personally i’d much prefer to have all language processing done LOCALLY instead of sending the data to some server. Now that would of course imply a bigger SoC and more flash mem so as to locally deep-neural-process the externally prepared language model data.
On the other hand, an application field where a small cheap stream-only SoC like the ESP32 would be perfect would be SIP-based audio routing and telephony (e.g. for telephony, intercom, and for routing the audio to all places in home to a central local language-command-processing SoC). Haven’t found a lib yet that would really implement for ESP32 what would be needed for that.
These devices listen locally for the hot word. Only after hearing the hot word do they transmit the next phrase up to the cloud. The do not transmit continuously. For the paranoid, you can disable the hot word detection on most devices and switch it to a button press.
Sure you could make a big, local machine do the voice recognition and convert it to text locally, but you’d still be sending the same query to the cloud in text form, so what’s the point?
Jon, I have respect for your views and experience, however, playing Devil’s advocate myself. We all thought those worried about Facebook, were paranoid. Perhaps we all need to be less naively trusting?
Use a network sniffer and look at the network traffic if you are worried. You will observe that there is not a continuous flow of data.
It also simply impractical to think that Amazon is processing live 24/7 audio data from 300M echo devices. The compute resources for that don’t exist. Plus the data is useless. 99.99% of what they pick up would simply be a TV or music playing.
This Facebook stuff is completely overblown too. The API that was used to harvest this data was removed over four years ago. The hubbub is because the press found out that third parties are still passing around the four year old data. The furor would be more justified if the API was still there.
And everyone misses the largest invasion of privacy — your smart phone. Your cell carrier knows every where you have been, they can see every call you make, they know every website and app you use, and it has a camera/mic on it and you carry it into the bathroom or leave it around in the bedroom.
First of all, there doesn’t have to be any “big” machine for voice recognition. What really eats up significant computing power and memory is the model training, which is not at all what we’re talking about here. The voice to speech conversion with the done trained model would work with a cheap SOC such as an Allwinner chip. That’s a category above the ESP32 but still lightweight and cheaper than a lunch.
And NO, it’s NOT as if all voice applications would be limited to sending a query up to the cloud. There’s a LOT of voice applications that wouldn’t need that at all. As a matter of fact, only a small minority of useful voice applications are frontends to cloud services.
And YES, even for those few, it’s absolutely in the interest of privacy to process the voice locally instead of sending Google, Amazon or whatever other privacy-infringing data monger your biometric voice data. And that’s even without any of the security issues with having your home bugged with a factual spying device. With all the vulnerabilities found in lots of devices, you really don’t just have to see the risk of your privacy being spied on by the data monger service of your choice but by anyone who might use such a vuln. Anyone with any notion of data security would never want that.
Again, that’s not saying that cheap simple audio-to-network-stream devices don’t have their rightful use cases, but as far as my use cases go, that would be to a local voice processing, not to some cloud service.
Does near field hot word work with this kit?
I see the note now in the first diagram that the code is coming, but not here yet.
but where do i get the lyra kit from?
Waiting for sdr transformation on 40m SW , mic as IQ demodulator