
I’ve just showed how to install Debian, and build a Linux image from source on VS-RD-RK3399 board (aka Mecool VS-RK3399) last week-end, but at the time I did not run any benchmarks on the board. We already have plenty of benchmarks for Rockchip RK3399 in Android, so instead I started by installing the latest Phoronix Test Suite in Debian:
|
1 2 3 |
sudo apt install php-cli php-gd php-xml php-zip wget http://phoronix-test-suite.com/releases/repo/pts.debian/files/phoronix-test-suite_7.4.0_all.deb sudo dpkg -i phoronix-test-suite_7.4.0_all.deb |
… and ran the tests I did on NanoPi NEO 2 earlier:
|
1 |
phoronix-test-suite benchmark 1704029-RI-1704017RI65 |
For whatever reasons OpenSSL and Mafft failed to download, but we still have the other benchmarks to compare with. Note that the Debian image is likely not optimized, and while the system runs an Aarch64 kernel, the rootfs is only 32-bit, which may have affected some of the benchmarks.
|
1 2 3 4 5 |
linaro@linaro-alip:~$ file /bin/ls /bin/ls: ELF 32-bit LSB shared object, ARM, EABI5 version 1 (SYSV), dynamically linked, interpreter /lib/ld-linux-armhf.so.3, for GNU/Linux 3.2.0, BuildID[sha1]=f10ece941515bd40f6aa48dd28ba481c8a17cace, stripped linaro@linaro-alip:~$ uname -a Linux linaro-alip 4.4.55 #474 SMP Tue Sep 5 09:09:33 CST 2017 aarch64 GNU/Linux linaro@linaro-alip:~$ |
But let’s see what’s we’ve got, starting with John the Ripper password cracker, a multi-threaded benchmark.
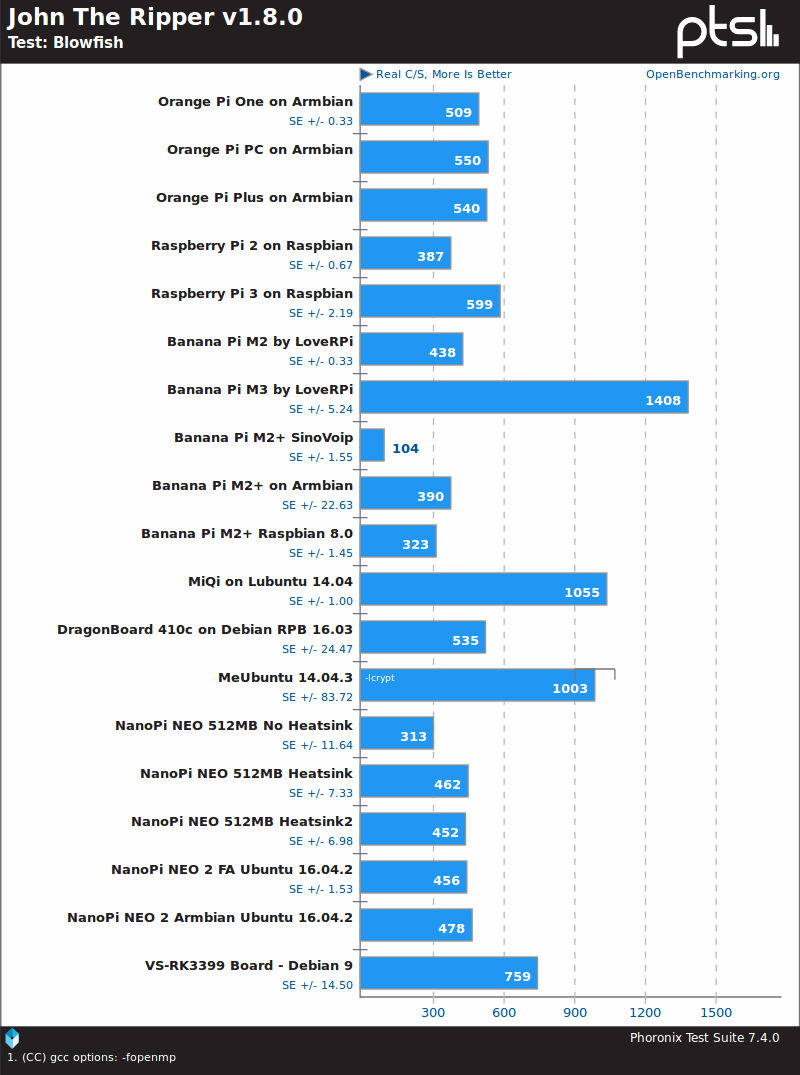
We’d normally expect hardware platforms based on Rockchip RK3399 SoC to outperform all other Cortex A53 or A17 based boards in the list, but MiQi board with a quad core Cortex A17 processor @ 1.8 GHz, and BPI-M3 board with an octa-core Cortex A7 processor @ 2.0 GHz, both beat the VS-RK3399 with an hexa-core processor with two Cortex A72 cores @ 1.8 GHz, and four Cortex A53 cores @ 1.4 GHz. BPI-M3 is even twice as fast in this test.
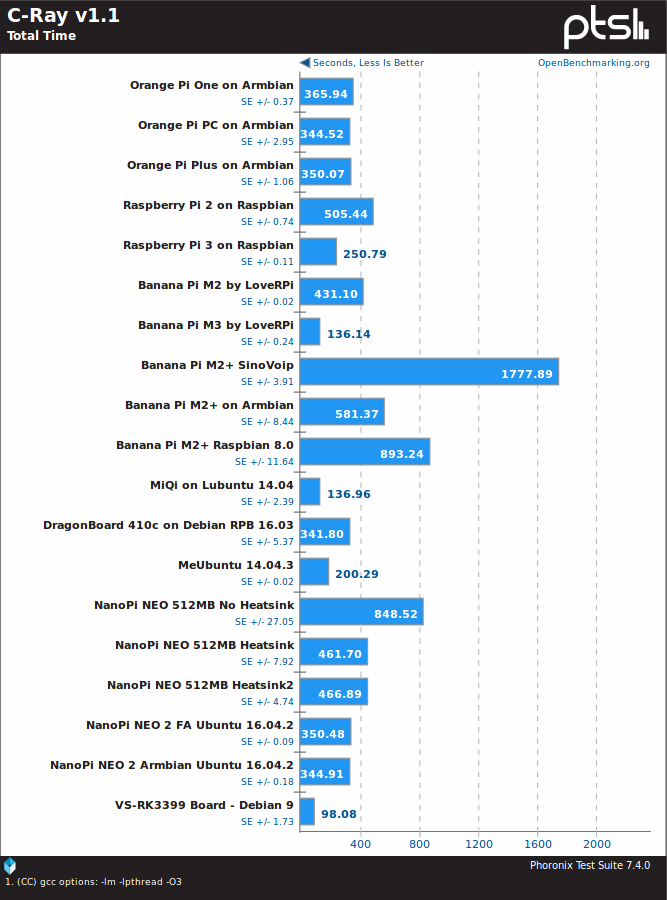
C-Ray is also a multi-threaded benchmark, but here Rockchip RK3399 SoC shines, making VS-RK3399 the fastest platform of the lot, also beating MeLE PCG02U TV stick (MeUbuntu 14.04.3) powered by an Intel Bay Trail Z3735F processor.
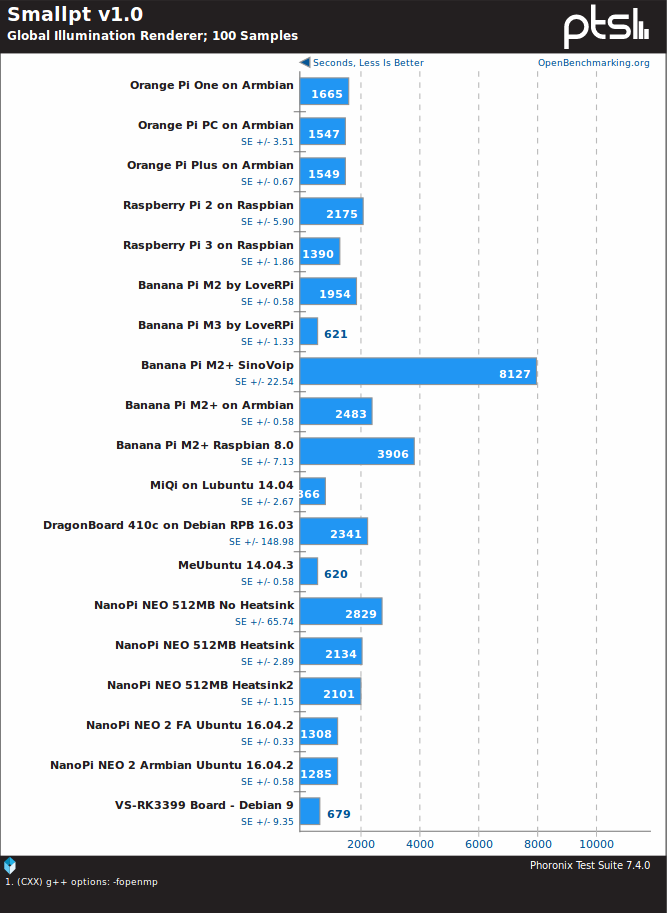
Smallpt is another multi-threaded benchmark, and VS-RK3399 board does well, but it’s still beaten by the Intel TV stick (OpenMP might help here?), and Banana Pi M3.
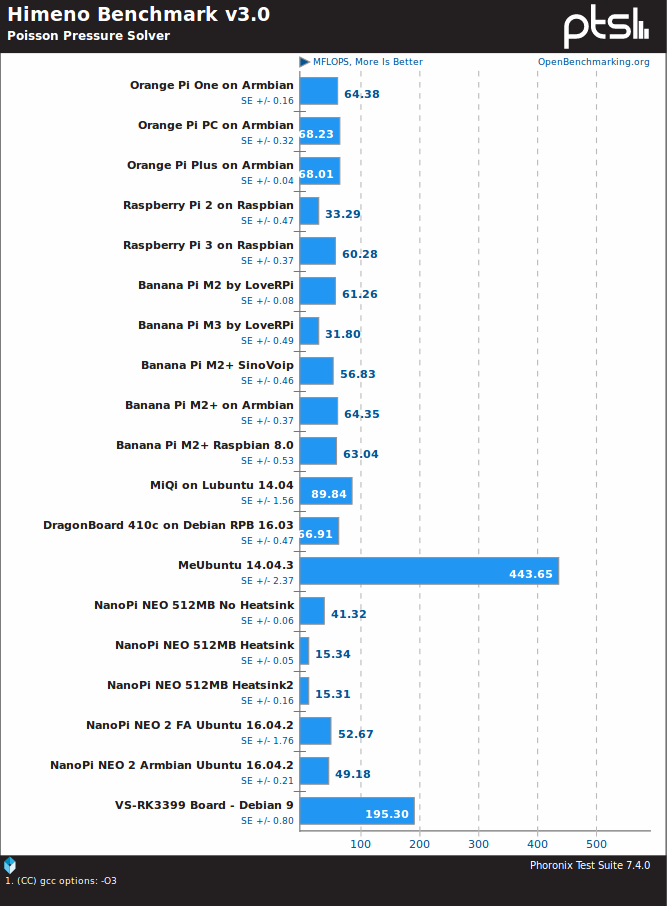
The Rockchip RK3399 board is the fastest ARM platform for Himeno linear solver of pressure Poisson, but due to specific x86 instructions and/or optimization, the Bay Trail TV stick is well ahead.
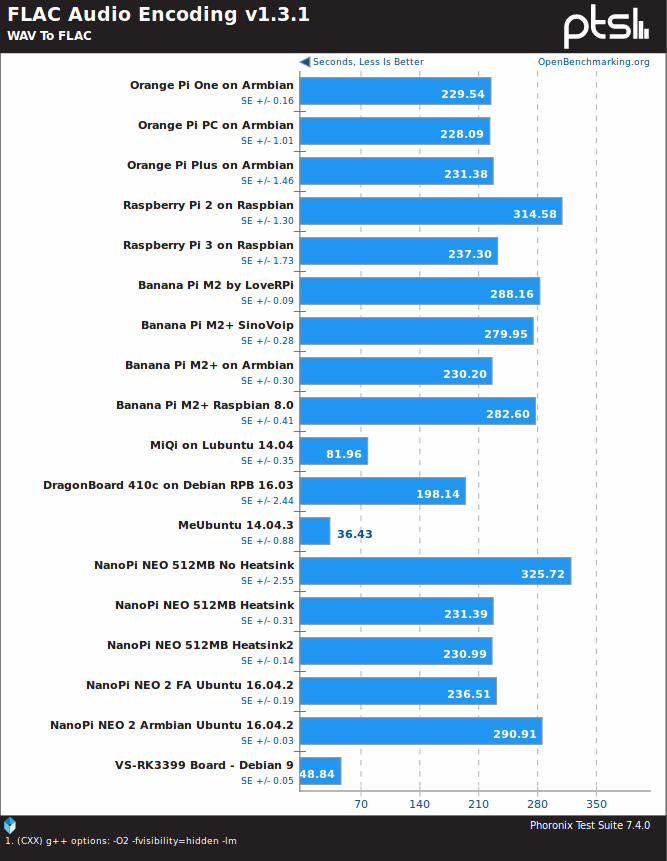
Finally, for FLAC audio encoding, VS-RK3399 is the best ARM platform (in the tested lot) by a wide margin, but Intel is ahead with their more advanced SIMD instructions.
So Rockchip RK3399 processor will outperform all ARM boards with single threaded tasks thanks to it Cortex A72 cores, but in some multi-threaded tests, octa-core Cortex A7, and quad core Cortex A17 platforms may deliver better results.
VS-RD-RK3399 board comes with a 32GB Samsung eMMC 5.0 flash that supposed to deliver 246/46 MB/s R/W speed, and 6K/5K R/W IOPS.
I tested it with iozone using a 100MB file:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
linaro@linaro-alip:~$ iozone -e -I -a -s 100M -r 4k -r 16k -r 512k -r 1024k -r 16384k -i 0 -i 1 -i 2 Iozone: Performance Test of File I/O Version $Revision: 3.429 $ Compiled for 32 bit mode. Build: linux Include fsync in write timing O_DIRECT feature enabled Auto Mode File size set to 102400 kB Output is in kBytes/sec Time Resolution = 0.000001 seconds. Processor cache size set to 1024 kBytes. Processor cache line size set to 32 bytes. File stride size set to 17 * record size. random random bkwd record stride kB reclen write rewrite read reread read write read rewrite read fwrite frewrite fread freread 102400 4 13776 18641 20379 20297 19979 10786 102400 16 40569 48950 67454 67674 62191 46898 102400 512 91630 96352 205605 207032 207506 89744 102400 1024 96414 98347 226686 223573 231049 95957 102400 16384 101911 101557 252291 251657 251811 101860 iozone test complete. |
Results for the read speed are around the theoretical limit, but write speeds are well above, maybe because of some caching.
I switched to Gigabit Ethernet performance testing starting with a full duplex iperf test:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
iperf -t 60 -c 192.168.0.104 -d ------------------------------------------------------------ Server listening on TCP port 5001 TCP window size: 85.3 KByte (default) ------------------------------------------------------------ ------------------------------------------------------------ Client connecting to 192.168.0.104, TCP port 5001 TCP window size: 332 KByte (default) ------------------------------------------------------------ [ 4] local 192.168.0.115 port 56102 connected with 192.168.0.104 port 5001 [ 5] local 192.168.0.115 port 5001 connected with 192.168.0.104 port 33932 [ ID] Interval Transfer Bandwidth [ 4] 0.0-60.0 sec 5.77 GBytes 827 Mbits/sec [ 5] 0.0-60.0 sec 3.25 GBytes 465 Mbits/sec |
Not quite optimal, so let’s look at upload only:
|
1 2 3 4 5 6 |
Client connecting to 192.168.0.104, TCP port 5001 TCP window size: 85.0 KByte (default) ------------------------------------------------------------ [ 3] local 192.168.0.115 port 56104 connected with 192.168.0.104 port 5001 [ ID] Interval Transfer Bandwidth [ 3] 0.0-60.0 sec 6.44 GBytes 921 Mbits/sec |
and download only:
|
1 2 3 4 5 6 |
Server listening on TCP port 5001 TCP window size: 85.3 KByte (default) ------------------------------------------------------------ [ 4] local 192.168.0.115 port 5001 connected with 192.168.0.104 port 33972 [ ID] Interval Transfer Bandwidth [ 4] 0.0-60.0 sec 6.56 GBytes 939 Mbits/sec |
Both of which are quite good. I had been told that IRQ may all be handled by CPU0 (Cortex A53 core in the board), and the following changes may improve performance:
|
1 2 3 4 5 |
sudo su echo 3 >/proc/irq/$(awk -F":" "/eth0/ {print \$1}" </proc/interrupts | sed 's/\ //g')/smp_affinity_list echo 7 >/sys/class/net/eth0/queues/rx-0/rps_cpus echo 32768 >/proc/sys/net/core/rps_sock_flow_entries echo 32768 >/sys/class/net/eth0/queues/rx-0/rps_flow_cnt |
So I repeated the tests, and something impossible happened:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
root@linaro-alip:/home/linaro# iperf -t 60 -c 192.168.0.104 -d ------------------------------------------------------------ Server listening on TCP port 5001 TCP window size: 85.3 KByte (default) ------------------------------------------------------------ ------------------------------------------------------------ Client connecting to 192.168.0.104, TCP port 5001 TCP window size: 255 KByte (default) ------------------------------------------------------------ [ 4] local 192.168.0.115 port 56106 connected with 192.168.0.104 port 5001 [ 5] local 192.168.0.115 port 5001 connected with 192.168.0.104 port 34198 [ ID] Interval Transfer Bandwidth [ 4] 0.0-60.0 sec 6.00 GBytes 859 Mbits/sec [ 5] 0.0-60.0 sec 9.41 GBytes 1.35 Gbits/sec |
We’re not supposed to get 1.35 Gbps on Gigabit Ethernet… So I tried again for a longer period of time (10 minutes):
|
1 2 3 4 5 6 7 8 9 |
------------------------------------------------------------ Client connecting to 192.168.0.104, TCP port 5001 TCP window size: 264 KByte (default) ------------------------------------------------------------ [ 4] local 192.168.0.115 port 56110 connected with 192.168.0.104 port 5001 [ 5] local 192.168.0.115 port 5001 connected with 192.168.0.104 port 34814 [ ID] Interval Transfer Bandwidth [ 4] 0.0-600.0 sec 61.4 GBytes 878 Mbits/sec [ 5] 0.0-600.0 sec 94.1 GBytes 1.35 Gbits/sec |
Same results.. But looking at the output from the server side, it looks more realistic:
|
1 2 3 4 5 6 |
Client connecting to 192.168.0.115, TCP port 5001 TCP window size: 366 KByte (default) ------------------------------------------------------------ [ 6] local 192.168.0.104 port 34814 connected with 192.168.0.115 port 5001 [ 6] 0.0-600.0 sec 47.0 GBytes 673 Mbits/sec [ 4] 0.0-600.1 sec 61.4 GBytes 878 Mbits/sec |
and it does improve a little compared to the first test without the tweaks.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress



Would be interesting to repeat the network tests with iperf3 instead while having a look with htop whether a CPU bottleneck occurs (very likely with bidirectional test) and then see what’s happening when sending IRQ processing to cpu5 instead of cpu3.
BTW: some of the multithreaded Phoronix benchmarks show standard deviation too high so most probably with better heat dissipation numbers would look better for your RK3399 device. Also BPi M3 features Cortex-A7 cores and not A53 and the reason why slow Cortex-A7 can shine here is since PTS (as so often) uses bizarre compilation settings.
@tkaiser
Yes, cooling is somewhat of an issue on multi-threaded benchmarks, but nothing massive:
C-ray is a multithreaded benchmark, stressing all available cores. Please correct the error.
@GanjaBear
Thanks. Fixed.
Typo: C-Ray is a single threaded -> multi-threaded
Thx @cnxsoft. If you want to see the full potential of the SoC in that benchmark, rerun the test at ‘CFLAGS=-Ofast’
@GanjaBear
You’re absolutely right but would have to patch the makefiles for some of these Phoronix ‘benchmarks’. I had numbers differing by 14 times when comparing reasonable compiler flags with the stuff the PTS uses for whatever reasons. Everything known sinces ages BTW: https://www.phoronix.com/forums/forum/software/mobile-linux/28245-arm-cortex-a9-pandaboard-es-benchmarks?p=320735#post320735
@GanjaBear
I’ve run
Results:
vs 98 seconds with O3. That’s quite a difference (Thermal throtlling is more obvious here too). Do you know what happened at the compiler level?
Some fun comparison against other platforms:
Re ‘-Ofast’ – keep in mind that enables -ffast-math, so some fp computations may go highwire. Just saying (should be safe in both c-ray and smallpt).
But it’s really curious to see how great 8x A7 @ 2GHz perform on the embarrassingly-parallel c-ray and smallpt. Who’d have thought?.. ; )
The specs and the performance benchmark numbers are very useful. But I feel it is missing the following two items that most users would want to know.
Has anyone tested read/write throughput to a USB 3.0 Hard disk ?
Also, any ideas if its possible to install Kodi with GPU acceleration along with Linux ?
Thanks,
@Ajira Tech
USB3 performance should be the same as with RK3328 since sharing same USB3 host controller with RK3399. A web search for ‘rock64 iozone close to 400 mb/s’ should show numbers (and ‘close to 400 mb/s’ should already give an idea what to expect with fast SSDs –> translates to ‘fast enough for any HDD since the HDD is always the bottleneck’ 😉 )
But of course you need an UASP (USB Attached SCSI) capable disk enclosure to get full speed.
@tkaiser
Thanks tkaiser. My bad for not following up on this any sooner.
When you say 400 mb/s and that it is fast enough for any HDD, I’m assuming you meant MegaBytes per second and not megabits per second? because a 7200 RPM spinning disk can easily get you a throughput of 600Mbps or higher.
Please confirm if you meant Mbps or Megabytes per second .