
A group of researcher at CERN have evaluated Applied Micro X-Gene 1 64-bit ARM XC-1 development board against Intel Xeon E5-2650 and Xeon Phi SE10/7120 systems, and one of them, David Abdurachmanov, presented their findings at ACAT’ 14 conference (Advanced Computing and Analysis Techniques) by listing some of the issues they had to port their software to 64-bit ARM, and performance efficiency of the three systems for data processing of High Energy Physics (HEP) experiments like those at the Large Hadron Collider (LHC), where performance-per-watt is important, as computing systems may scale to several hundred thousands cores.
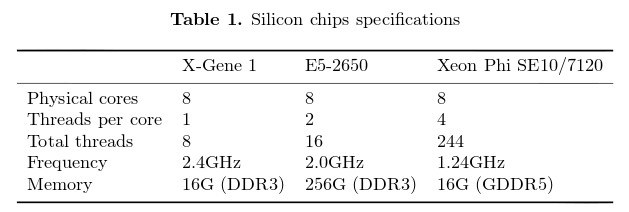
Intel Xeon Phi platform based on Many Integrated Cores (MIC) computer architecture was launched the HPC market, and contrary to the table above features 61 physical cores. Applied X-Gene 1 (40nm process) was used instead of X-Gene 2 built on 28-nm process which was not available at the time. The ARM platform ran Fedora 19, whereas the Intel processor used Scientific Linux CERN 6.5.
The researchers run the CERN’s CMSSW applications for testing. Let’s jump to the results.
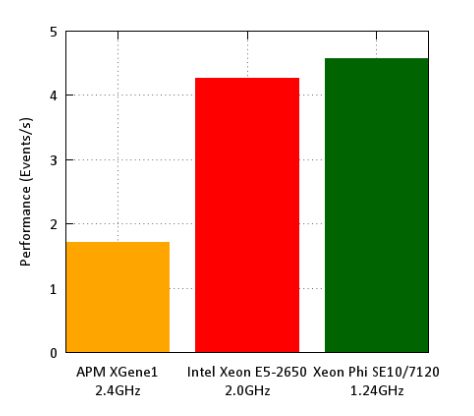 As expected Intel Xeon processor and Phi coprocessor both have more performance than X-Gene 1 ARM SoC.
As expected Intel Xeon processor and Phi coprocessor both have more performance than X-Gene 1 ARM SoC.
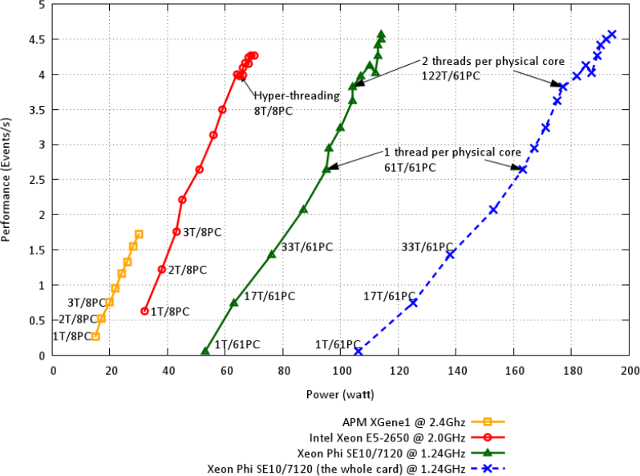 However, when it comes to performance-per-watt, APM X-Gene 1 is clearly ahead of Intel Xeon E5-2650 and there’s no comparison against Xeon Phi systems.
However, when it comes to performance-per-watt, APM X-Gene 1 is clearly ahead of Intel Xeon E5-2650 and there’s no comparison against Xeon Phi systems.
The conclusion of the report reads as follows:
We have built the software used by the CMS experiment at CERN, as well as portions of the OSG software stack, for ARMv8 64-bit. It has been made available in the official CMS software package repository and via the CVMFS distributed file system used by Grid sites.
Our initial validation has demonstrated that APM X-Gene 1 Server-on-Chip ARMv8 64-bit solution is a relevant and potentially interesting platform for heterogeneous high-density computing. In the absence of platform specific optimizations in the ARMv8 64-bit GCC compiler used, APM X-Gene 1 shows excellent promise that the APM X-Gene hardware will be a valid competitor to Intel Xeon in term of power efficiency as the software evolves. However, Intel Xeon Phi is a completely different category of product. As APM X-Gene 2 is being sampled right now, built on the TMSC 28nm process, we look forward to extending our work to include it into our comparison.
You can read the full report “Heterogeneous High Throughput Scientific Computing with APM X-Gene and Intel Xeon Phi” for details.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress



What about the purchase cost/event capacity – does that favour ARM too? How similar are these tasks to say web-serving?
(I don’t dare to even download something titled “Heterogeneous High Throughput Scientific Computing with APM X-Gene and Intel Xeon Phi 😉
Does Xeon Phi SE10/7120 systems supports 244 threads or is that a typo?
8 x 4 (eight times four) is not 244, it is only 32
@Harley
The table is wrong. There are 61 physical cores, each supporting 4 threads, so a total of 244 threads are supported.
just looking at the yellow (ARM) and the red (XEON-E5) lines, i can say that 1,5/30 is less than 4/60. So is the ARM so efficient? Then, you’re just counting the CPU; plus, if you need 2 ARM machines for one Intel you’re even less efficient. Rather strange conclusions coming from CERN? Or do i need to go back to school?
@MadMax
I think they refer to the potential efficiency benefit from the now sampling 28nm cores.
I need a real world “performance per energy” comparison. I mean (total_work_done)/(total_Energy_consumed).
Example: GZIP given, say 100MB XML file. Total Energy wasted for this work was say 0.5W/h with this CPU, 0.3W/h for that. Because it`s the Energy, not the power what we pay for.
Also strain factors like I/O subsystem should be eliminated, e.t. use a RAM disk.