
Kendryte K210 is a dual-core RISC-V AI processor that was launched in 2018 and found in several smart audio and computer vision solutions. We previously wrote a Getting Started Guide for Grove AI HAT for Raspberry Pi using Arduino and MicroPython, and XaLogic XAPIZ3500 offered an even more compact K210 solution as a Raspberry pi pHAT with Raspberry Pi Zero form factor.
The company is now back with another revision of the board called “XaLogic K210 AI accelerator” designed to work with Raspberry Pi Zero and larger boards with the 40-pin connector.

K210 AI Accelerator board specifications:
- SoC – Kendryte K210 dual-core 64-bit RISC-V processor @ 400 MHz with 8MB on-chip RAM, various low-power AI accelerators delivering up to 0.5 TOPS,
- Host Interface – 40-pin Raspberry Pi header using:
- SPI @ 40 MHz via Lattice iCE40 FPGA
- I2C, UART, JTAG, GPIOs signals
- Security
- Infineon Trust-M cloud security chip
- 128-bit AES Accelerator and SHA256 Accelerator on Kendryte K210 SoC
- Expansion – 8-pin unpopulated header with SPI and power signals
- Misc – 3x LEDs,
- Power consumption – 0.3 W
- Dimensions – 65x30mm Raspberry Pi Zero HAT
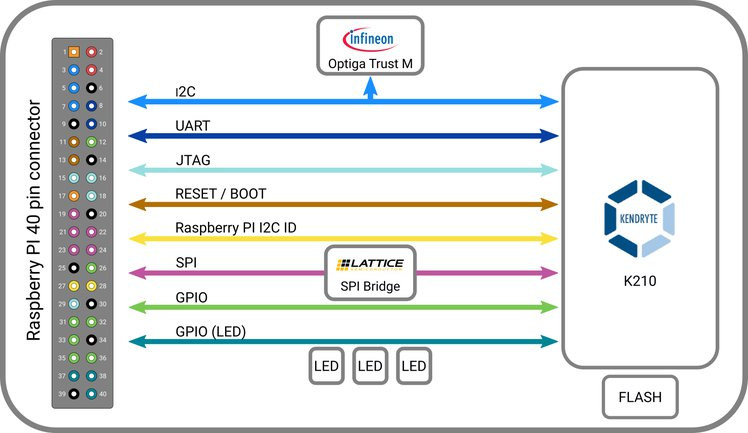
The company also offers an extender for Raspberry Pi 3B+, 4B board and future model that includes a PoE header. It’s unclear why an FPGA is needed for the SPI interface between K210 and the Broadcom processor on the SBC as both support SPI, so maybe it’s master/slave issue, or for improved performance. I also noticed one of the K210 SPI interface (it has four) is exposed through an 8-pin header. Another difference compared to other K210 board is the including of Infineon Trust-M security chip that is meant to help “establish a secure connection to AWS through MQTT without exposing the private key.”
XaLogic K210 AI Accelerator works best with Raspberry Pi Zero and camera, and allows you to use pre-trained models for evaluation including object detection, face detection, age and gender estimation, simple voice commands, and vibration abnormally detection. It will also be possible to train your own model using a more powerful host machine, ideally with an NVIDIA GPU, with TensorFlow. Conversion tools enable the use of TFLite, Caffe, and even ONNX format. The company recommends Visual Studio Code to modify K210 C code directly on Raspberry Pi if needed.
Now public information is limited, but eventually schematics, C code in the K210, all code running on the Raspberry Pi, sample Python based Caffe & Tensorflow projects will be open sourced, while pre-trained models will be provided in binary form on the company’s Github account.
XaLogic K210 AI Accelerator has just launched on Crowd Supply with a $3,000 funding target. A $38 pledge is asked for the board, and if you plan to use it with Raspberry Pi 3B+ or 4B, you may want to add $3 for a 40-pin extender due to POE header obstruction. Shipping adds $8 to the US, and $16 to the rest of the world. It’s around $10 more expensive than the Grove AI HAT, likely because of the FPGA and security chips, but sadly XaLogic did not do a very good job of clearly explaining the advantage brought out by the extra chips. Shipping to backers is expected to start at the end of May 2021.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress


