
Dimitris Tassopoulos (Dimtass) decided to learn more about machine learning for embedded systems now that the technology is more mature, and wrote a series of five posts documenting his experience with low-end hardware such as STM32 Bluepill board, Arduino UNO, or ESP8266-12E module starting with simple NN examples, before moving to TensorFlow Lite for microcontrollers.
Dimitris recently followed up his latest “stupid project” (that’s the name of his blog, not being demeaning here :)) by running and benchmarking TensorFlow Lite for microcontrollers on various Linux SBC.
But why? you might ask. Dimitris tried to build tflite C++ API designed for Linux, but found it was hard to build, and no pre-built binary are available except for x86_64. He had no such issues with tflite-micro API, even though it’s really meant for baremetal MCU platforms.
Let’s get straight to the results which also include a Ryzen platform, probably a laptop, for reference:
| SBC | Average for 1000 runs (ms) |
| Ryzen 2700X (this is not SBC) | 2.19 |
| AML-S905X-CC | 15.54 |
| Raspberry Pi 3 B+ | 13.47 |
| Jetson nano | 9.34 |
| NanoPi Duo | 36.76 |
| NanoPi Neo | 16 |
| NanoPi NEO2 | 22.83 |
| NanoPi NEO4 | 5.82 |
| NanoPi K1 Plus | 14.32 |
| Orange Pi Prime | 18.40 |
| Beaglebone Black | 97.03 |
| STM32F746 @ 216MHz | 76.75 |
| STM32F746 @ 288 MHz | 57.95 |
And in chart form.
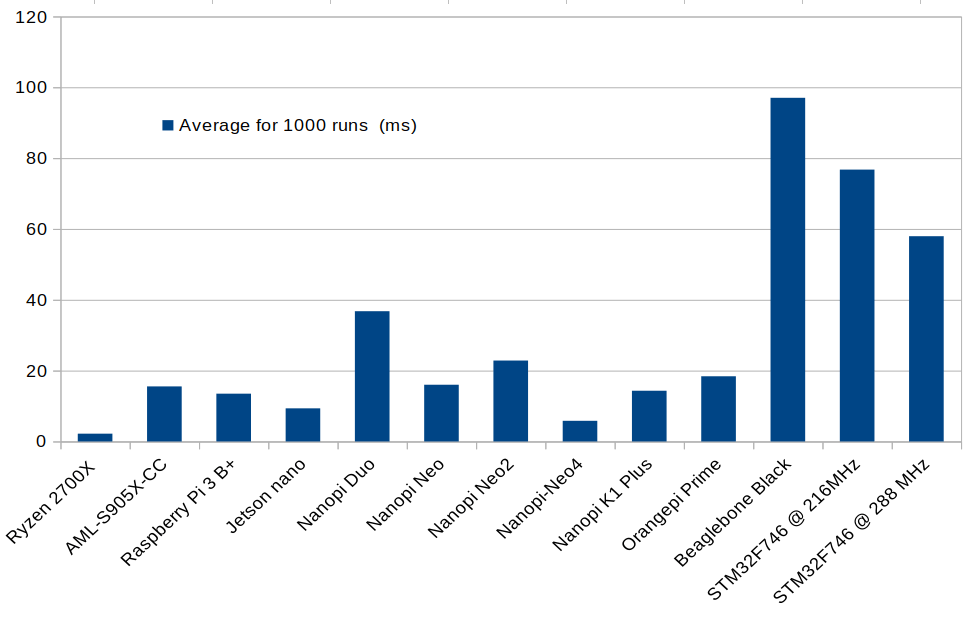
The Ryzen 2700X processor is the fastest, but Rockchip RK3399 CPU found in NanoPi NEO4 is only 2.6 times slower, and outperforms all other Arm SBCs, including Jetson Nano. Not bad for a $50 board. Allwinner H3 based NanoPi Neo board also deserves a mention as at $10, it offers the best performance/price ratio for those test.
If you want to try it on your own board or computer, you can do so as follows:
|
1 2 3 4 5 |
sudo apt install cmake g++ git clone https://dimtass@bitbucket.org/dimtass/tflite-micro-python-comparison.git cd tflite-micro-python-comparison/ ./build.sh ./build-aarch64/src/aarch64-mnist-tflite-micro |
Note that’s for Aarch64 (Arm 64-bit targets), the last command line will be different for other architectures, for example on Cortex-A7 based SoC, the program will be named “mnist-tflite-micro-armv7l” instead.
Note that while tflite-micro is easy to port to any SBCs, there are some drawbacks over using tflite C++ API. Notably tflite-micro does not support multi-threading, and it’s much slower than tflite C++ API.
| CPU | tflite-micro/tflite speed ratio |
| Ryzen 2700X | 10.63x |
| Jetson nano (5W) | 9.46x |
| Jetson nano (MAXN) | 3.86x |
The model is also embedded in the executable instead of being loading from a file, unless you implement your own parse. You’ll find a more detailed analysis and explanation on Dimtass’ blog post.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress


