
I recently reviewed ODROID-H2 with Ubuntu 19.04, and noticed some errors messages in the kernel log of the Intel Celeron J4105 single board computer while running SBC-Bench benchmark:
|
1 2 3 4 5 6 7 8 9 |
[180422.405294] mce: [Hardware Error]: Machine check events logged [180425.656449] mce: [Hardware Error]: Machine check events logged [180483.582825] mce_notify_irq: 17 callbacks suppressed [180483.582827] mce: [Hardware Error]: Machine check events logged [180484.991484] mce: [Hardware Error]: Machine check events logged [180594.700684] mce_notify_irq: 13 callbacks suppressed [180594.700686] mce: [Hardware Error]: Machine check events logged [180858.202115] mce: [Hardware Error]: Machine check events logged [181178.047031] mce: [Hardware Error]: Machine check events logged |
I did not know what do make of those errors, but I was told I would get more details with mcelog which can be installed as follows:
|
1 |
sudo apt install mcelog |
There’s just one little problem: it’s not in Ubuntu 19.04 repository, and a bug report mentions mcelog is not deprecated, and remove from Ubuntu 18.04 Bionic onwards. Instead, we’re being told the mcelog package functionality has been replaced by rasdaemon.
But before looking into the utilities, let’s find out what Machine Check Exception (MCE) is all about from ArchLinux Wiki:
A machine check exception (MCE) is an error generated by the CPU when the CPU detects that a hardware error or failure has occurred.
Machine check exceptions (MCEs) can occur for a variety of reasons ranging from undesired or out-of-spec voltages from the power supply, from cosmic radiation flipping bits in memory DIMMs or the CPU, or from other miscellaneous faults, including faulty software triggering hardware errors.
Hardware error should probably be taken seriously. Let’s investigate how to run the tools. First, I try to install mcelog from Ubuntu 16.04:
|
1 2 |
wget http://archive.ubuntu.com/ubuntu/pool/universe/m/mcelog/mcelog_128+dfsg-1_amd64.deb sudo dpkg -i mcelog_128+dfsg-1_amd64.deb |
Oh good! It could install… Let’s run some commands:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
sudo mcelog [sudo] password for odroid: mcelog: Family 6 Model 7a CPU: only decoding architectural errors mcelog: warning: 32 bytes ignored in each record mcelog: consider an update odroid@ODROID-H2:~$ sudo mcelog --client Memory errors SOCKET 1 CHANNEL 5 DIMM 0 DMI_NAME "A1_DIMM0" DMI_LOCATION "A1_BANK0" corrected memory errors: 0 total 0 in 24h uncorrected memory errors: 0 total 0 in 24h SOCKET 1 CHANNEL 5 DIMM 1 DMI_NAME "A1_DIMM1" DMI_LOCATION "A1_BANK1" corrected memory errors: 0 total 0 in 24h uncorrected memory errors: 0 total 0 in 24h |
Nothing interesting shows up here, but the file /var/log/mcelog is now up, and we can see details about the errors:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
cat /var/log/mcelog mcelog: Family 6 Model 7a CPU: only decoding architectural errors Hardware event. This is not a software error. MCE 0 CPU 0 BANK 1 TSC bd2ee6710 TIME 1563095601 Sun Jul 14 16:13:21 2019 MCG status: MCi status: Corrected error Error enabled Threshold based error status: green MCA: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error STATUS 902000460082110a MCGSTATUS 0 MCGCAP c07 APICID 0 SOCKETID 0 CPUID Vendor Intel Family 6 Model 122 ... |
But let’s also try the recommended rasdaemon to see if we can get similar details.
Installation:
|
1 |
sudo apt install rasdaemon |
It looks like the service will not start automatically upon installation, so a reboot may be needed, or simply run the following command:
|
1 |
service rasdaemon start |
I ran a few commands and at first, it looked like some driver may be needed:
|
1 2 3 4 |
ras-mc-ctl --mainboard ras-mc-ctl: mainboard: HARDKERNEL model ODROID-H2 sudo ras-mc-ctl --status ras-mc-ctl: drivers not loaded. |
This should be related to EDAC drivers that are used for ECC memory according to a thread on Grokbase. Gemini Lake processors do not support ECC memory, so I probably don’t need it.
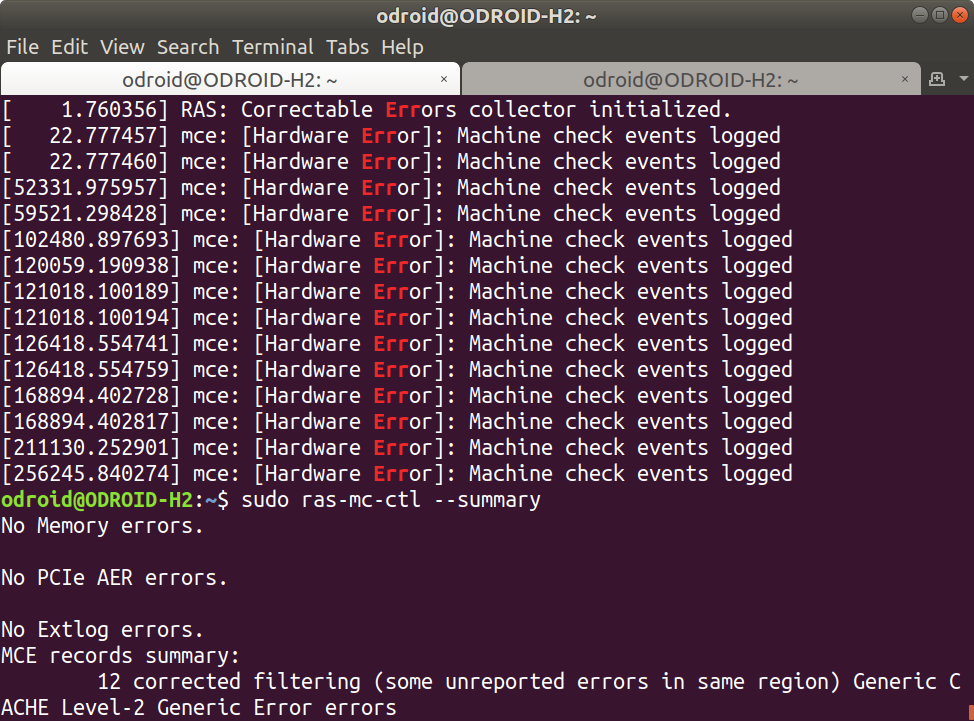
Running one more command to show the summary of errors, and we’re getting somewhere:
|
1 2 3 4 5 6 7 8 |
sudo ras-mc-ctl --summary No Memory errors. No PCIe AER errors. No Extlog errors. MCE records summary: 12 corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error errors |
12 corrected error related to the L2 cache. We can get the full details with the appropriate command:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
sudo ras-mc-ctl --errors No Memory errors. No PCIe AER errors. No Extlog errors. MCE events: 1 2019-07-15 20:41:09 +0700 error: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error, mcg mcgstatus=0, mci Corrected_error Error_enabled Threshold based error status: green, Large number of corrected cache errors. System operating, but might leadto uncorrected errors soon, mcgcap=0x00000c07, status=0x942000460082110a, addr=0x243e9f840, tsc=0x8b99a7f84108, walltime=0x5d2c8276, cpuid=0x000706a1, bank=0x00000001 2 2019-07-16 01:34:09 +0700 error: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error, mcg mcgstatus=0, mci Corrected_error Error_enabled Threshold based error status: green, Large number of corrected cache errors. System operating, but might leadto uncorrected errors soon, mcgcap=0x00000c07, status=0x942000460082110a, addr=0x24b9df840, tsc=0xa38afb430944, walltime=0x5d2cc722, cpuid=0x000706a1, bank=0x00000001 3 2019-07-16 01:50:08 +0700 error: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error, mcg mcgstatus=0, mci Corrected_error Error_enabled Threshold based error status: green, Large number of corrected cache errors. System operating, but might leadto uncorrected errors soon, mcgcap=0x00000c07, status=0x902000420082110a, tsc=0xa4d95741ee28, walltime=0x5d2ccae1, cpuid=0x000706a1, bank=0x00000001 4 2019-07-16 01:50:08 +0700 error: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error, mcg mcgstatus=0, mci Corrected_error Error_enabled Threshold based error status: green, Large number of corrected cache errors. System operating, but might leadto uncorrected errors soon, mcgcap=0x00000c07, status=0x902000420082110a, tsc=0xa4d957436320, walltime=0x5d2ccae1, cpuid=0x000706a1, bank=0x00000001 5 2019-07-16 01:50:08 +0700 error: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error, mcg mcgstatus=0, mci Corrected_error Error_enabled Threshold based error status: green, Large number of corrected cache errors. System operating, but might leadto uncorrected errors soon, mcgcap=0x00000c07, status=0x902000420082110a, tsc=0xa4d957451d82, walltime=0x5d2ccae1, cpuid=0x000706a1, bank=0x00000001 6 2019-07-16 01:50:08 +0700 error: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error, mcg mcgstatus=0, mci Corrected_error Error_enabled Threshold based error status: green, Large number of corrected cache errors. System operating, but might leadto uncorrected errors soon, mcgcap=0x00000c07, status=0x902000420082110a, tsc=0xa4d957456482, walltime=0x5d2ccae1, cpuid=0x000706a1, bank=0x00000001 7 2019-07-16 03:20:09 +0700 error: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error, mcg mcgstatus=0, mci Corrected_error Error_enabled Threshold based error status: green, Large number of corrected cache errors. System operating, but might leadto uncorrected errors soon, mcgcap=0x00000c07, status=0x902000400082110a, tsc=0xac3468f91976, walltime=0x5d2cdffa, cpuid=0x000706a1, bank=0x00000001 8 2019-07-16 03:20:09 +0700 error: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error, mcg mcgstatus=0, mci Corrected_error Error_enabled Threshold based error status: green, Large number of corrected cache errors. System operating, but might leadto uncorrected errors soon, mcgcap=0x00000c07, status=0x902000400082110a, tsc=0xac3468fb7a3a, walltime=0x5d2cdffa, cpuid=0x000706a1, bank=0x00000001 9 2019-07-16 15:08:09 +0700 error: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error, mcg mcgstatus=0, mci Corrected_error Error_enabled Threshold based error status: green, Large number of corrected cache errors. System operating, but might leadto uncorrected errors soon, mcgcap=0x00000c07, status=0x902000460082110a, tsc=0xe60f3181c782, walltime=0x5d2d85ea, cpuid=0x000706a1, bank=0x00000001 10 2019-07-16 15:08:09 +0700 error: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error, mcg mcgstatus=0, mci Corrected_error Error_enabled Threshold based error status: green, Large number of corrected cache errors. System operating, but might leadto uncorrected errors soon, mcgcap=0x00000c07, status=0x902000460082110a, tsc=0xe60f31852002, walltime=0x5d2d85ea, cpuid=0x000706a1, bank=0x00000001 11 2019-07-17 02:52:09 +0700 error: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error, mcg mcgstatus=0, mci Corrected_error Error_enabled Threshold based error status: green, Large number of corrected cache errors. System operating, but might leadto uncorrected errors soon, mcgcap=0x00000c07, status=0x942000460082110a, addr=0x249c5f840, tsc=0x11f964ae442b2, walltime=0x5d2e2aea, cpuid=0x000706a1, bank=0x00000001 12 2019-07-17 15:24:09 +0700 error: corrected filtering (some unreported errors in same region) Generic CACHE Level-2 Generic Error, mcg mcgstatus=0, mci Corrected_error Error_enabled Threshold based error status: green, Large number of corrected cache errors. System operating, but might leadto uncorrected errors soon, mcgcap=0x00000c07, status=0x902000440082110a, tsc=0x15d0984e5de54, walltime=0x5d2edb2a, cpuid=0x000706a1, bank=0x00000001 |
The status is green which means everything still works, but the utility reports a “large number of corrected cache errors”, and the “system (is) operating, but might lead to uncorrected errors soon” (See source code). It happens only a few times a day, and I’m not sure what can be done about the cache since it’s not something that can be changed as it’s embedded into the processor, maybe it’s just an issue with the processor I’m running. If somebody has an ODROID-H2 running, it may be useful to check out the kernel log with dmesg to see if you’ve got the same errors. If you do, please also indicate whether you have a board from the first batch (November 2018) or one of the new ODROID-H2 Rev B boards.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress


