
Compilers like GCC OR LLVM normally do a good job at optimizing your code when processing your source code into assembly, and then binary format, but there’s still room for improvement – at least for larger binaries -, and Facebook has just released BOLT (Binary Optimization and Layout Tool) that has been found to reduce CPU execution time by 2 percent to 15 percent.
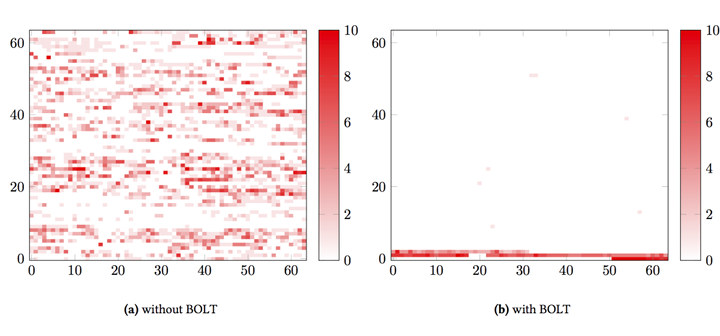
The tool is mostly useful for binaries built from a large code base, with binary size over 10MB which are often too large to fit in instruction cache. The hardware normally spends lots of processing time getting an instruction stream from memory to the CPU, sometimes up to 30% of execution time, and BOLT optimizes placement of instructions in memory – as illustrated below – in order to address this issue also known as “instruction starvation”.
 BOLT works with applications built by any compiler, including the popular GCC and Clang compilers. The tool relies on Linux perf tool to gather performance data, several LLVM libraries, and currently supports x86-64 and Aarch64 (ARM64) binaries. The company achieved 8% improvement for their HHVM (HipHop Virtual Machine) execution engine for the PHP and Hack programming languages.
BOLT works with applications built by any compiler, including the popular GCC and Clang compilers. The tool relies on Linux perf tool to gather performance data, several LLVM libraries, and currently supports x86-64 and Aarch64 (ARM64) binaries. The company achieved 8% improvement for their HHVM (HipHop Virtual Machine) execution engine for the PHP and Hack programming languages.
If you’d like to try it yourself, you’ll find the tool source code, and instructions to build and run it in Github. If you’d also like to better understand how it works internally, you may want to read the white paper.
Via Phoronix

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress


