
Bzip2 is still one of the most commonly used compression tools in Linux, but it only works with a single thread, and I’ve been made aware that lbzip2 allows multi-threaded bzip2 compressions which should lead to much better performance on multi-core systems.
lbzip2 was not installed by default in my Ubuntu 16.04 machine, but it’s easy enough to install:
|
1 |
sudo apt install lbzip2 |
I have cloned mainline linux repository on my machine, so let’s see how long it takes to compress the directory with bzip2 (one core compression):
|
1 2 3 4 5 |
time tar cjf linux.tar.bz2 linux real 9m22.131s user 7m42.712s sys 0m19.280s |
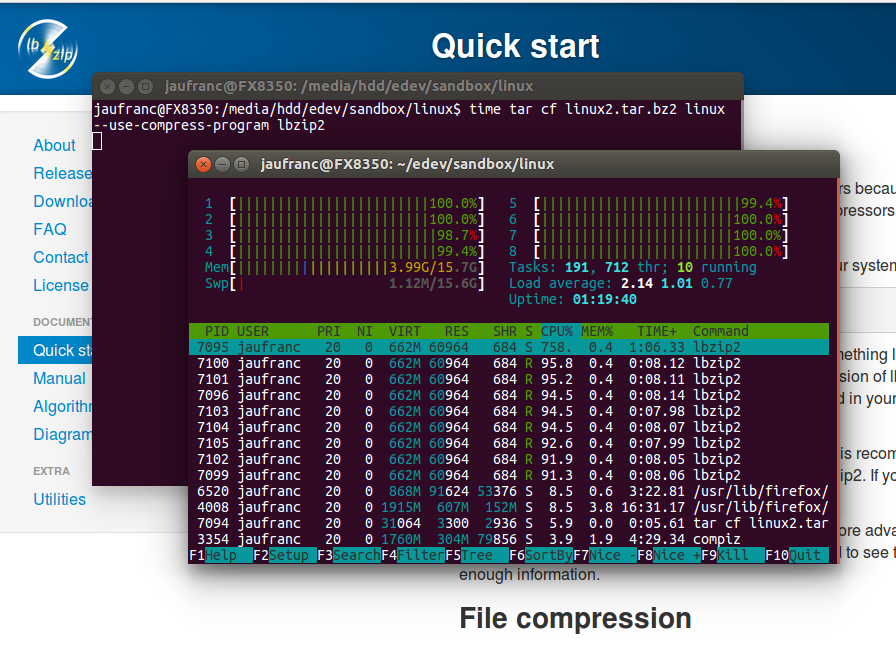
9 minutes and 22 seconds. Now let’s repeat the test with lbzip2 using all 8 cores from my AMD FX8350 processor:
|
1 2 3 4 5 |
time tar cf linux2.tar.bz2 linux --use-compress-program=lbzip2 real 2m32.660s user 7m4.072s sys 0m17.824s |
2 minutes 32 seconds. Almost 4x times, not bad at all. It’s not 8 times faster because you have to take into account I/Os, and at the beginning the system is scanning the drive, using all 8-core but not all full throttle. The files were also stored in a hard drive, so I’d assume the performance difference should be even more noticeable from an SSD.
We can see both files are about the same size as they should be:
|
1 2 3 4 5 |
ls -l total 4377472 drwxrwxr-x 25 jaufranc jaufranc 4096 Dec 12 21:13 linux -rw-rw-r-- 1 jaufranc jaufranc 2241648426 Dec 16 10:17 linux2.tar.bz2 -rw-rw-r-- 1 jaufranc jaufranc 2240858174 Dec 15 20:50 linux.tar.bz2 |
I’m not exactly sure why there’s about 771 KB difference as both tools offer the same compression.
That was for compression. What about decompression? I’ll decompress the lbzip2 compressed file with bzip2 first:
|
1 2 3 4 5 |
time tar xf linux2.tar.bz2 -C linux-bzip2 real 2m49.671s user 2m46.500s sys 0m13.068s |
2 minutes and 49 seconds. Now let’s decompress the bzip2 compressed file with lbzip2:
|
1 2 3 4 5 |
time tar xf linux.tar.bz2 --use-compress-program=lbzip2 -C linux-lbzip2 real 0m45.081s user 3m14.732s sys 0m10.088s |
45 seconds! Again the performance difference is massive.
If you want tar to always use lbzip2 instead of bzip2, you could create an alias:
|
1 |
alias tar='tar --use-compress-program=lbzip2' |
Please note that this will cause a conflict (“Conflicting compression options”) when you try to compress files using -j /–bzip2 or -J, –xz options, so instead of tar, you may want to create another alias, for example tarfast.
lbzip2 is not the only tool to support multi-threaded bzip2 compression, as pbzip2 is another implementation. However, one report indicates that lbzip2 may be twice as fast as pbzip2 to compress files (decompression speed is about the same), which may be significant if you have a backup script…
tkaiser also tested various compression algorithms (gzip, pbzip2, lz4, pigz) for a backup script for Orange Pi boards running armbian, and measured overall performance piping his eMMC through the different compressors to /dev/null:
|
1 2 3 4 5 |
gzip -c: 10.4 MB/s 1065 MB pbzip2 -1 -c: 15.2 MB/s 1033 MB lz4 - -z -c -9 -B4: 18.0 MB/s 1276 MB pigz -c: 25.2 MB/s 1044 MB pigz --zip -c: 25.2 MB/s 1044 MB |
pigz looks the best solution here (25.2 MB/s) compared to pbzip2 (15.2 MB/s). lbzip2 has not been tested, and could offer an improvement over pigz both in terms of speed and compression based on the previous report, albeit actual results may vary depending on the CPU used.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress

