
We’re often writing about new video codecs like AV1 or H.266, and recently, we covered AVIF picture format that offers an improved quality/compression ratio against WebP and JPEG, but there’s also work done on audio codecs.
Notably, we noted Opus 1.2 offered decent speech quality with a bitrate as low as 12 kbps when it was outed in 2017, the release of Opus 1.3 in 2019 improved the codec further with high-quality speech possible at just 9 kbps. But Google AI recently unveiled Lyra very low-bitrate codec for speech compression that achieves high speech quality with a bitrate as low as 3kbps.
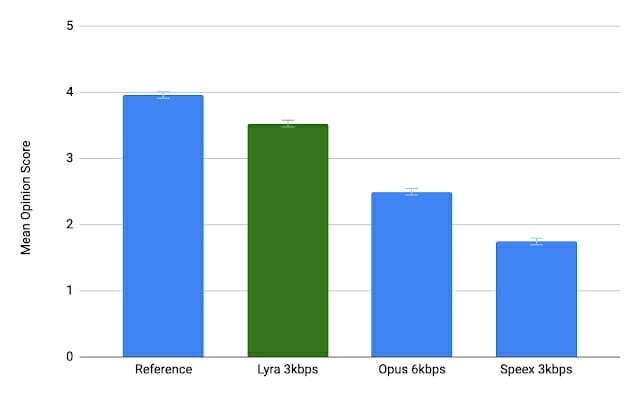
Before we go into the details of Lyra codec, Google compared a reference audio file encoded with Lyra at 3 kbps, Opus at 6 kbps (the minimum bitrate for Opus), and Speex at 3 kbps, and users reported Lyra to sound the best, and close to the original. You can actually try it by yourself.
| Clean Speech |
| Original |
| Opus @ 6kbps |
| Lyra @ 3kbps |
| Speex @ 3kbps |
| Noisy Environment |
| Original |
| Opus @ 6kbps |
| Lyra @ 3kbps |
| Speex @ 3kbps |
Speex 3kbps sounded pretty bad for all samples. I feel Opus 6kbps and Lyra 3kbps sound about the same with the clean speech samples, but Lyra reproduces the background music better in the noisy environment.
So how does Lyra work? Google AI explains the basic architecture of the Lyra codec relies on features (log mel spectrograms), or distinctive speech attributes, representing speech energy in different frequency bands, extracted from speech every 40ms and then compressed for transmission. On the receiving end, a generative model uses those features to recreate the speech signal.
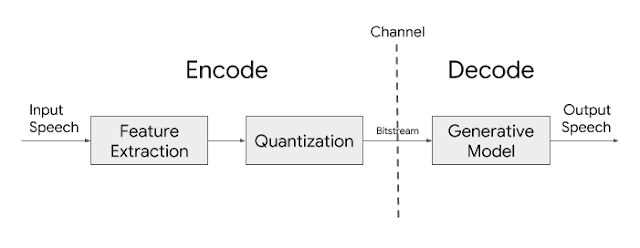
Lyra also leverages natural-sounding generative models to maintain a low bitrate while achieving high quality, similar to the one achieved by higher bitrate codecs.
Using these models as a baseline, we’ve developed a new model capable of reconstructing speech using minimal amounts of data. Lyra harnesses the power of these new natural-sounding generative models to maintain the low bitrate of parametric codecs while achieving high quality, on par with state-of-the-art waveform codecs used in most streaming and communication platforms today. The drawback of waveform codecs is that they achieve this high quality by compressing and sending over the signal sample-by-sample, which requires a higher bitrate and, in most cases, isn’t necessary to achieve natural sounding speech.
One concern with generative models is their computational complexity. Lyra avoids this issue by using a cheaper recurrent generative model, a WaveRNN variation, that works at a lower rate, but generates in parallel multiple signals in different frequency ranges that it later combines into a single output signal at the desired sample rate. This trick enables Lyra to not only run on cloud servers, but also on-device on mid-range phones in real time (with a processing latency of 90ms, which is in line with other traditional speech codecs). This generative model is then trained on thousands of hours of speech data and optimized, similarly to WaveNet, to accurately recreate the input audio.
Lyra will enable intelligible, high-quality voice calls even with poor quality signals, low bandwidth, and/or congested network connections. It does not only work for English, as Google has trained the model with thousands of hours of audio with speakers in over 70 languages using open-source audio libraries and then verifying the audio quality with expert and crowdsourced listeners.
The company also expects video calls to become possible on a 56kbps dial-in modem connection thanks to the combination of AV1 video codec with Lyra audio codec. One of the first app to use the Lyra audio codec will be Google Duo video-calling app, where it will be used on very low bandwidth connections. The company also plans to work on acceleration using GPUs and AI accelerators and has started to investigate whether the technologies used for Lyra can also be leveraged to create a general-purpose audio codec for music and non-speech audio. More details can be found on Google AI blog post.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress


