
So far Arm defined all instructions for their cores with the benefit of code portability between solutions, so code compiled for an Arm Cortex-M33 based microcontroller would run on another without modifications (we’re obviously talking about code running directly on the core, not using specific peripherals here).
But with RISC-V open-source architecture many have seen the benefit of custom instructions for specific tasks, at the risk of potential fragmentation. With Arm Techcon 2019 now taking place, Arm has just announced support for custom instructions for ARMv8-M embedded CPUs starting with Arm Cortex-M33 cores.
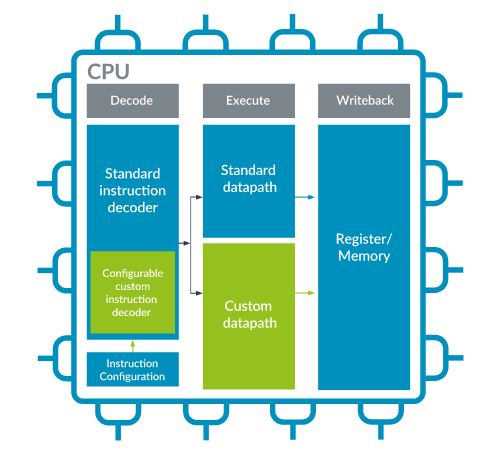
The implementation of Arm Custom Instructions for specific embedded and IoT applications will start in H1 2020 at no additional cost to licensees and without risk of software fragmentation using NOCP exception if the instructions are not available.
Arm futher explains:
Arm Custom Instructions are enabled by modifications to the CPU that reserve encoding space for designers to easily add custom datapath extensions while maintaining the integrity of the existing software ecosystem. This feature, together with the existing co-processor interface, enable Cortex-M33 CPUs to be extended with various types of accelerators optimized for edge compute use cases including machine learning (ML) and artificial intelligence (AI).
Specifically, Arm Custom Instructions for Armv8-M add a customizable module inside the processor which shares the same interface as the standard Arithmetic Logic Unit (ALU) of the CPU. There are multiple regions of the encoding space available for customization and you can choose up to eight regions based on the type of instructions you want to implement.
SoC designers will still have to follow classes of instruction extension for general-purpose and FPU/M-Profile Vector Extension (MVE). The announcement features quotes from STMicro, NXP, and Silicon Labs so one should probably expect new Arm Cortex-M33 MCU with custom instructions from those companies sometimes in 2020 or 2021.
Here’s an example of code (population count function) that could be optimized with custom instructions:
|
1 2 3 4 5 6 7 |
int popcount(uint32_t x) { int n = 0; for (int i = 0; i < 32; ++i) { n += (x >> i) & 1; } return n; } |
Hand-written, optimized assembly would look as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
MOV.W r1, #0x55555555 AND.W r1, r1, r0, LSR #1 SUBS r0, r0, r1 MOV.W r1, #0x33333333 AND.W r1, r1, r0, LSR #2 BIC r0, r0, #0xCCCCCCCC ADD r0, r1 MOV.W r1, #0x01010101 ADD.W r0, r0, r0, LSR #4 BIC r0, r0, #0xF0F0F0F0 MULS r0, r1, r0 LSRS r0, r0, #24 |
This code could be replaced by a single custom instruction that saves space, improves performance & efficiency executing in just one cycle:
|
1 |
CX1A p0, r0, #0 // population in r0, return r0 |
More details, including a whitepaper, can be found on the product page.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress


