
One of the most popular applications of artificial intelligence is object detection where you have models capable of detecting objects or subjects being cats, dogs, cars, laptops, or other. As I discovered in a press release by Gyrfalcon, there’s something similar for videos called CDVA (Compact Descriptors for Video Analysis) that’s capable of analyzing the scene taking place, and describe it in a precise manner.
The CDVA standard, aka MPEG ISO/IEC 15938-15, describes how video features can be extracted and stored as compact metadata for efficient matching and scalable search. Gyrfalcon published a press release, their Lightspeeur line of AI chips will adapt CDVA.
You can get the technical details in that paper entitled “Compact Descriptors for Video Analysis: the Emerging MPEG Standard”. CDVA still relies on (CNN Convoluted Neural Network) but do so but extracting frames first, append a timestamp and the encoded CDVA descriptor to the video, which is sent to a server or the cloud for analysis.
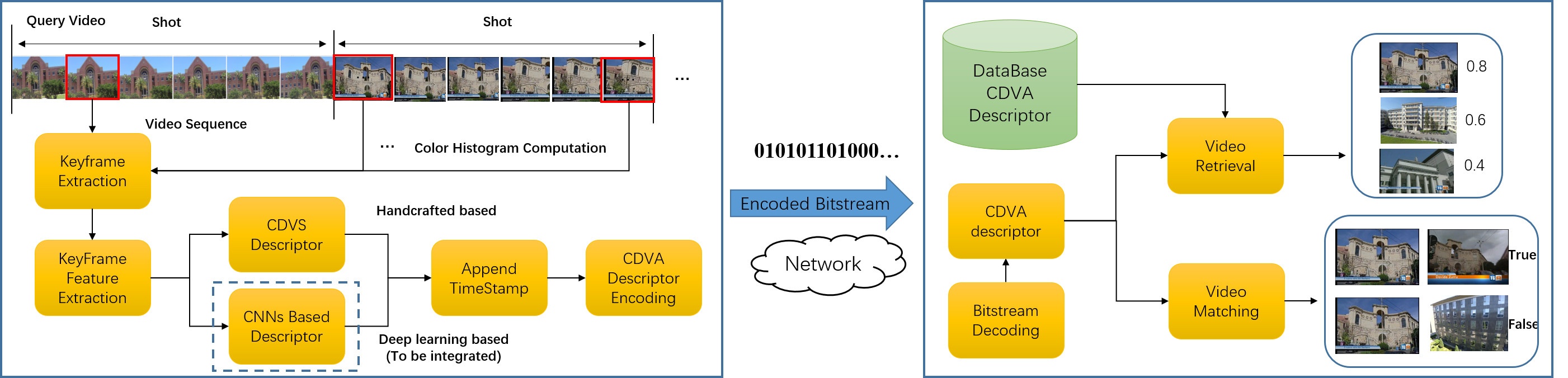
If you wonder what CDVS is:
MPEG-CDVS provides the standardized description of feature descriptors and the descriptor extraction process for efficient and inter-operable still image search applications. Basically, CDVS can serve as the frame-level video feature description, which inspires the inheritance of CDVS features in the CDVA exploration.
So the way I understand it is that CDVS is for still images in the video, and analysis is done at the edge, while CDVA analyses the video itself, and the heavy lifting is done in the cloud.
Typical applications mobile augmented reality, automotive, surveillance, and media entertainment. For example, I’m now using a PIR based surveillance camera that will send alerts when motion is detected. But I won’t know if that’s a cat, a rabbit, some leaves moving or an actual thief until I watch the video, so there are plenty of false positive. A CDVA enabled surveillance camera would filter cats and rabbits, and send accurate descriptions of unusual events such as “masked men approaching house suspiciously” :).
If you remember I recently wrote about MPEG VCM (Video Codec for Machine) specifically designed for M2M and H2M (human-to-machine) applications, and the MPEG group working on the project is also talking about an application of CDVA called SuperCDVA that performs video understanding by using temporal information.

SuperCDVA is still work in progress and will be discussed at MPEG-128 meeting in Geneva on on the 7th of October 2019. You can read “SuperCDVA for MPEG128” (PDF) for more details.
The video below showcases SuperCDVA in action understanding video “on the fly” It takes 2 to 3 seconds to analyze videos with Gyrfalcon (GTI) solution.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress


