
Just a couple of days ago, Amazon introduced EC2 A1 Arm instances based on custom-designed AWS Graviton processors featuring up to 32 Arm Neoverse cores. Commenters started a discussion about price and the real usefulness of Arm cores compared to x86 cores since the latter are likely to be better optimized, and Amazon Web Services (AWS) pricing for EC2 A1 instances did not seem that attractive to some.
The question whether it makes sense will obviously depend on the workload, and metrics like performance per dollar, and performance per watt. AWS re:Invent 2018 is taking place now, and we are starting to get some answers with Amazon claiming up to 45% reduction in costs.

It sounds good, except there’s not much information about the type of workload here. So it would be good if there was an example of company leveraging this type of savings with their actual products or services. It turns SmugMug photo sharing website has migrated to Amazon EC2 A1 Arm instances. Their servers run Ubuntu 18.04 on 64-bit Arm with PHP, Nginx, HAProxy, Puppet, etc…, and it allegedly only took a few minutes to compile some of the required packages for Arm.

So at least they managed to migrate from Intel to Arm with everything running reliably on SmugMug website. But how much did they manage to save? Based on the slide below, costs went down by 40% per core for their use case. Impressive, and they also claim running Arm instances feel the same as Intel instances. Having said that, I find it somewhat odd to use “per core” cost savings, as for example if they went from 16-core Intel instances to 32-core Arm instances both going for the same price, the Arm instances would be 50% cheaper per core, assuming similar performance.

Phoronix also ran benchmarks on Amazon EC2 A1 instances, and here the results are quite different. As expected Intel or AMD based systems are still much faster in terms of raw performance, but if you expected a performance per dollar advantage for Arm instances, it’s not there for most workloads.
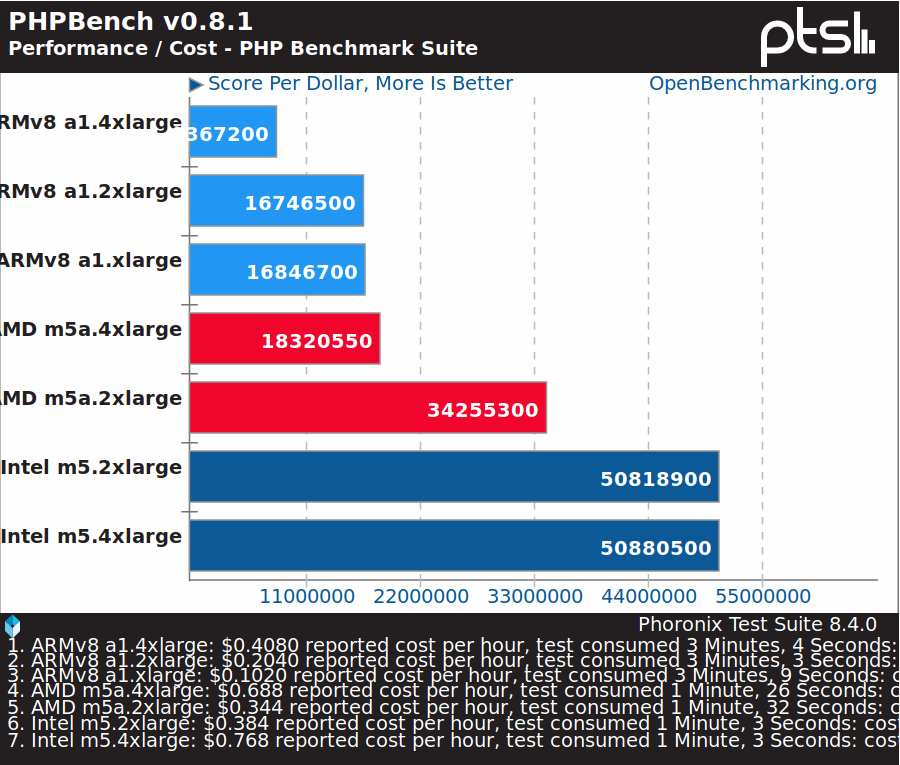
PHP runs on many servers, and you’d expect Arm to perform reasonably well in terms of performance per dollar, but some Intel instances are nearly three times cheaper here.
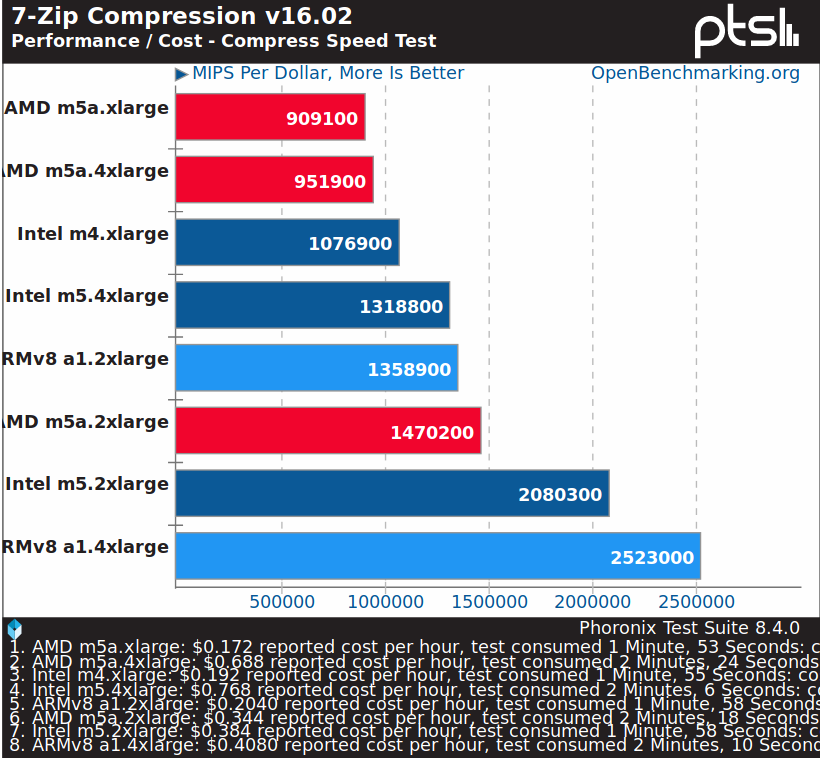
7-zip compression benchmark is one of the rare benchmarks were an Arm instance deliver a better performance/cost ratio than competing offerings. This lead Michael Larabel to conclude “at this stage, the Amazon EC2 ARM instances don’t make a lot of sense”.
My conclusion is that whether Arm instances make sense or not highly depends on your workload.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress


