
Espressif Systems have been working on audio applications like Smart Speakers based on ESP32 WiSoC with hardware development kits like ESP32-LyraTD-MSC Audio Mic HDK, and I could test it with Baidu DuerOS using Mandarin language.
However, at the time (February 2018), there was not much else that could be done with the hardware kit, since no corresponding ESP32 audio software development kit had been made available. This has now changes since Espressif has just released ESP-ADF Audio Development Framework on Github.
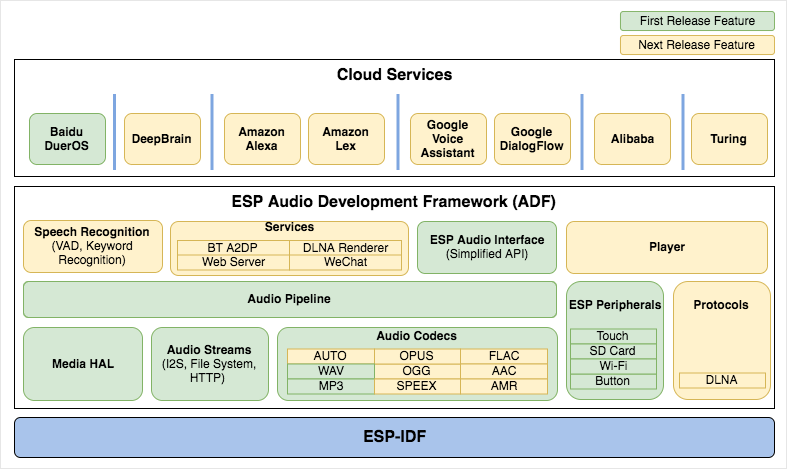 The framework will support the development of audio applications for the Espressif Systems ESP32 chip such as:
The framework will support the development of audio applications for the Espressif Systems ESP32 chip such as:
- Music player or recorder handling MP3, AAC, WAV, OGG, AMR, SPEEX … audio formats
- Play music from network (HTTP), storage (SD card), Bluetooth A2DP/HFP
- Integration with Media services such as DLNA, Wechat, etc..
- Internet Radio
- Voice recognition and integration with voice services such as Alexa, DuerOS, Google Assistant
As we can see from the diagram above, the first release supports Baidu DuerOS, WAV and MP3 audio, and ESP audio interface. The company will keep working on the framework to add more Cloud Services (DeepBrain, Alexa, Assistant, Alibaba…), Bluetooth support, DLNA support, and more audio codecs.

While several ESP32 boards will eventually be supported, there’s no documentation specific to ESP32-LyraTD-MSC “round” board yet, and instead a Getting Started Guide has been published for ESP32-LyRaT V4 board pictured above.
You’ll need to install ESP-IDF (Espressif IoT Development Framework) before using ESP-ADF, and to learn more details you may want to read the online documentation. ESP-ADF is released under ESPRESSIF MIT License.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress


