
Since I’ve just installed Ubuntu 17.10 on MeLE PCG35 Apo, I decided I should also run some benchmarks comparing with other ARM and x86 Linux platforms I’ve tested in the past.I was particularly interested to compare the performance of Intel Apollo Lake processors (Celeron J3455 in this case) against higher end ARM processors like Rockchip RK3399 (2x A72, 4x A53) since systems have a similar price (~$150+), as well as against the older Bay Trail processor to see the progress achieved over the last 2 to 3 years.
To do so, I used Phoronix Benchmark Suite against Videostrong VS-RK3399 results (RK3399 development board):
|
1 2 3 4 |
sudo apt install php-cli php-gd php-xml php-zip wget http://phoronix-test-suite.com/releases/repo/pts.debian/files/phoronix-test-suite_7.4.0_all.deb sudo dpkg -i phoronix-test-suite_7.4.0_all.deb phoronix-test-suite benchmark 1709271-TY-1704029RI26 |
The benchmark first issued a warning about “powersave” governor, but I still went ahead, and once completed I change it to “performance” governor:
|
1 2 |
sudo apt install cpufrequtils sudo cpufreq-set -r -g performance |
…and ran the tests again. All results are available on OpenBenchmarking.
Let’s address the governor results first. cpufreq-info reports that powersave governor can also switch between 800 MHz and 2.30 GHz (turbo freq).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
sudo cpufreq-info cpufrequtils 008: cpufreq-info (C) Dominik Brodowski 2004-2009 Report errors and bugs to cpufreq@vger.kernel.org, please. analyzing CPU 0: driver: intel_pstate CPUs which run at the same hardware frequency: 0 CPUs which need to have their frequency coordinated by software: 0 maximum transition latency: 0.97 ms. hardware limits: 800 MHz - 2.30 GHz available cpufreq governors: performance, powersave current policy: frequency should be within 800 MHz and 2.30 GHz. The governor "powersave" may decide which speed to use within this range. current CPU frequency is 629 MHz. |
As we’ll see from the results below pitting “MeLE PCG35 Apo – Ubuntu 17.10” (with powersave) and “MeLE PCG35 Apo- Ubuntu 17.10 Performance” that the governor settings did not matter one bit on the results, at least for the six benchmarks I ran.
Note that “MeUbuntu 14.04.3” represents MeLE PCG02U TV stick running Ubuntu 14.04.3. Every platform runs a different OS and kernel, so keep in mind the results may differ slightly (up or down) with different version. But as we’ll see the differences in performance are large enough that it likely does not matter that much.
 John the Ripper password cracker, a multi-threaded benchmark, shows the Apollo Lake processor is clearly ahead of Rockchip RK3399 hexa-core processor, and the fastest ARM platform, Banana Pi M3, is equipped with an Allwinner A83T octa-core Cortex A7 processor @ 2.0 GHz. The Bay Trail system is over twice as slow as the Apollo Lake one, also note the larg-ish standard deviation (+/- 83.72) due to some cooling problem in the small form factor.
John the Ripper password cracker, a multi-threaded benchmark, shows the Apollo Lake processor is clearly ahead of Rockchip RK3399 hexa-core processor, and the fastest ARM platform, Banana Pi M3, is equipped with an Allwinner A83T octa-core Cortex A7 processor @ 2.0 GHz. The Bay Trail system is over twice as slow as the Apollo Lake one, also note the larg-ish standard deviation (+/- 83.72) due to some cooling problem in the small form factor.
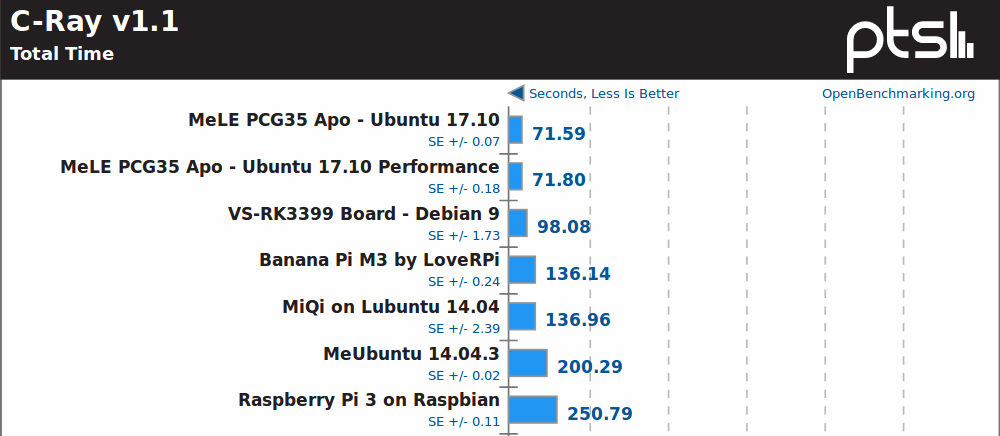
C-Ray is another multi-threaded benchmark, and here Rockchip RK3399 SoC does fairly well, but still but quite as well as the Celeron J3455.

Smallpt, yet another multi-threaded benchmark, does not really change the order with MeLE PCG35 Apo well ahead.

Himeno, a linear solver of pressure Poisson, must be using some x86 specific instructions or optimizations, as Intel platforms are well ahead, with Celeron J3455 about 2.5x faster than Rockchip RK3399 board.

OpenSSL is the domain of Intel platforms likely benefiting from Advanced Encryption Standard instruction set (AES-NI). Performance improvement between Bay Trail and Apollo Lake is also impressive here. You’d need 10 Raspberry Pi 3 to match MeLE PCG35 Apo in this particular test.

Intel is normally better with SIMD accelerated multimedia application, and FLAC audio encoding (single threaded) confirms that.
I was expecting a close fight between Rockchip RK3399 and Celeron J3455, but RK3399 only has two fast Cortex A72 cores against four x86 cores in the Intel Apollo Lake SoC.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress


