
After Zopfli, Google has now announced and released Brotli, a new compression algorithm to make the web faster, with a ratio compression similar to LZMA, but a much faster decompression, making it ideal for low power mobile devices.
Contrary to Zopfli that is deflate compatible, Brotli is a complete new format, and combines “2nd order context modeling, re-use of entropy codes, larger memory window of past data and joint distribution codes” to achieve higher compression ratios.
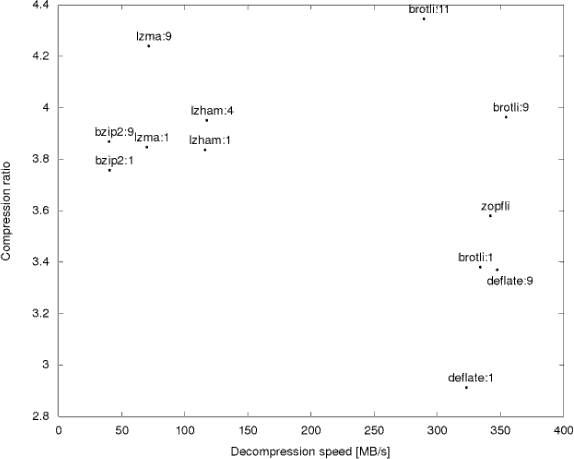
Google published some benchmark results comparing Brotli to other common algorithms. Since the company aims to make the web faster, the target is to decrease both downloading time (high compression ratio), and rendering time (fast decompression speed), and Brotli with a quality set to 11 is much better than competitor once both parameters are taken into account.
As you’d expect the source code can also be pulled from Github. So I gave it a quick try myself in an Ubuntu PC, and installed it as follows:
|
1 2 3 4 |
git clone https://github.com/google/brotli.git cd brotli/tools make -j8 sudo cp bro /usr/local/bin |
The application usage info is not really detailed, but good enough to get started:
|
1 2 3 |
bro -h Usage: bro [--force] [--quality n] [--decompress] [--input filename] [--output filename] [--repeat iters] [--verbose] |
I was a little too optimistic at first, and started by compressing a 2.4GB firmware file using quality 11 with bro, but I quickly found out it would take a very long time, as the compression speed is rather slow… Google white paper shows Brotli compresses 0.5 MB of data per second when quality is set to 11, and they performed the test on a server powered by an Intel Xeon E5-1650 v2 running at 3.5 GHz…
So instead I switched to Linux 4.2 Changelog text file I created a few days ago that’s only 14MB in size.
|
1 2 3 4 5 6 |
time bro --quality 11 --input Linux_4.2_Changelog.txt --output Linux_4.2_Changelog.txt.bro --verbose Brotli compression speed: 0.283145 MB/s real 0m46.648s user 0m46.093s sys 0m0.420s |
My machine is based on an AMD FX8350 processor (8 cores @ 4.0 GHz), and it took about 46.6 second to compress the file.
Then I switched to xz which implements LZMA compression, and compression preset 9.
|
1 2 3 4 5 |
time xz -9 Linux_4.2_Changelog.txt real 0m6.235s user 0m6.170s sys 0m0.024s |
Compression speed is much faster with xz, about 7.5 times faster , but it’s not really a concern for Google, because in their use cases, the file is compressed once, but downloaded and decompressed millions of times. It’s also interesting to note that both tools only used one core to compress the file.
Let’s check the file sizes.
|
1 2 3 |
ls -l L* -rw------- 1 jaufranc jaufranc 2530677 Sep 23 21:19 Linux_4.2_Changelog.txt.bro -rw-rw-r-- 1 jaufranc jaufranc 2457152 Sep 2 15:24 Linux_4.2_Changelog.txt.xz |
In my case, LZMA compression ratio was also slightly higher than Brotli compression ratio, but that’s only for one file, and Google’s much larger test sample (1,000+ files) shows a slight advantage to Brotli (11) over LZMA (9).
Decompression is much faster than compression in both cases:
|
1 2 3 4 5 |
time xz -d Linux_4.2_Changelog.txt.xz real 0m0.196s user 0m0.159s sys 0m0.036s |
|
1 2 3 4 5 |
time bro --decompress --input Linux_4.2_Changelog.txt.bro --output Linux_4.2_Changelog.txt.decode real 0m0.064s user 0m0.044s sys 0m0.020s |
Brotli is indeed considerably faster at decompressing than LZMA, about 3 times faster, just as reported in Google’s study.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress


